Sep-2023 by ア熵增焓减ウ | yult-entropy@qq.com | entropylt@163.com
0 写在前面
应科技博主@极客湾Geekerwan 邀请,我给最新的AMD EPYC CPU做了一些基准测试。原本打算将相关分析做进视频里,但由于进度赶不上,视频中只放了“7950X指数”,分析部分写成了单独的图文发出来,写得比较通俗,因为考虑到会有很多吃瓜群众来看。
硬件:7950X和双路EPYC 9754平台同视频中所述;双路9654平台其他硬件同双路9754平台,由@楼下小黑bba 提供。
操作系统&软件版本:
- Ubuntu 22.04.3 LTS, Linux 6.2.0-33-generic x86_64, GCC 11.4.0, NVIDIA GPU Driver 535.104.05
- Gaussian 16 Rev C.02 AVX2 (官方二进制分发包)
- ORCA 5.0.4 – OpenMPI 4.1.1 (官方预编译版本+自行编译的配套OpenMPI库)
- CP2K 2023.2 – OpenMPI 4.1.5 – CMake 3.26.3 – GCC 13.1.0 (
./install_cp2k_toolchain.sh --with-intel=no --with-gcc=install --with-cmake=install --with-openmpi=install --with-sirius=no --with-quip=install --with-plumed=install) - CP2K 2023.2 GPU – OpenMPI 4.1.5 – CUDA Toolkit 12.2.2
- VASP 6.4.2 – AOCC 4.1.0 – AOCL 4.1.0
- VASP 6.4.2 GPU – NVIDIA HPC SDK 23.7
特别感谢@切嗣耙耙 帮助测试VASP。
1 Gaussian & ORCA
1.1 介绍
使用Gaussian和ORCA来测试双路9754和双路9654的并行效率,顺便和7950X对比一下。
测试用的模型选用了可以在网络上找到大量对比数据的Test0397缬氨霉素,坐标文件就在Gaussian安装包里面。但是原版只是个普通的密度泛函(DFT)单点能量计算,并且计算级别太低了,不太适合今天的测试。把基组从3-21G调大成def2-TZVP,加个振动分析,针对ORCA再用上含时密度泛函(TDDFT)和DLPNO-CCSD(T)这两个ORCA的优势项目。这样我们得到了4个测试算例,应该能覆盖很多场景了。进一步考虑多任务的情况,把单点计算的基组改成比def2-TZVP小一些的def2-SVP,同时运行8个计算任务,每个任务32核(9754)或24核(9654),狠狠滴压榨。

1.2 测试结果
使用武汉大学钟成老师开发的Gaussian和ORCA并行效率测试脚本xbench3.0,测试双路9754和双路9654跑这几个算例的并行效率。
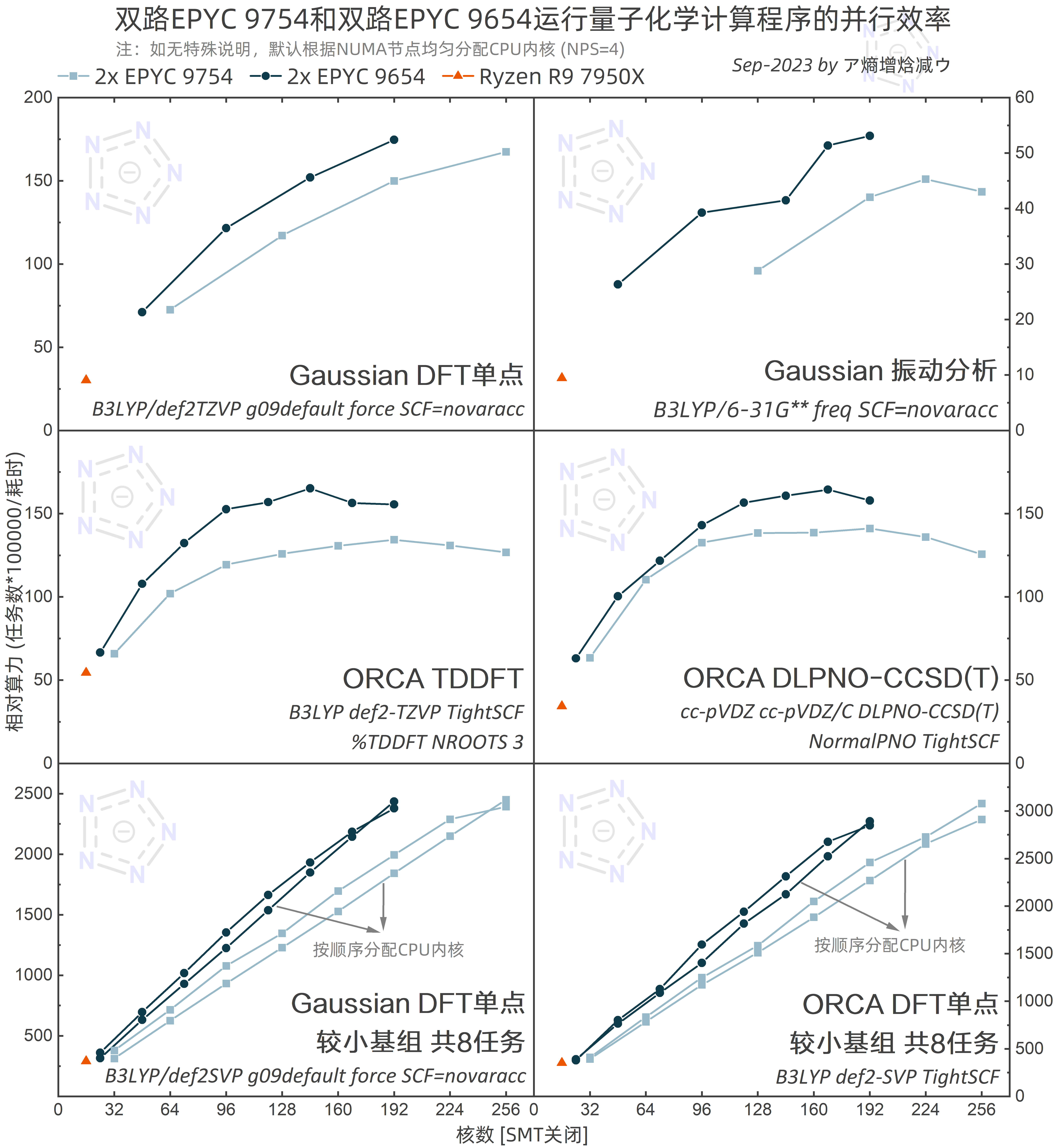
可以看到,单任务的并行效率都不太行,边际效应很明显,还出现了核用得越多跑得越慢的情况,其中双路9754性能很不理想。在多任务测试中,考虑了两种CPU内核分配策略,一种是大多数人会首先想到的按顺序分配,另一种是脚本默认的均匀分配。可以看到多任务的效率比单任务高得多,曲线很接近线性,其中按顺序分配的策略几乎完全线性,性能总和也达到了7950X的8-9倍,很接近理论值了。
值得一提的是,我们在测试中发现7950X+96GB内存的配置跑ORCA的DLPNO-CCSD(T)算例跑到半个小时左右的时候内存占用突然提高,然后就因为内存不足而报错退出了,这如果是正经科研的计算,估计科研人员要气晕了。最后把内存加到192GB总算是把测试跑下来了,但是加到192GB又会导致内存降频,而7950X的内存带宽瓶颈本来就严重,这对于其他不那么吃内存的测试来说得不偿失;哪怕是经验上内存越大越好的振动分析任务,再用192GB内存跑一遍,发现速度还是慢了20%。
2 CP2K & VASP
2.1 介绍
HPC和科学计算领域还有很多别的软件,比如著名的第一性原理计算软件——CP2K,它最大的优势是跑第一性原理分子动力学(AIMD)特别快,所以用官方benchmark包里的水盒子算例来测试,分别跑64个、256个、1024个水分子的盒子,每个盒子跑10步。考虑到1024水分子的AIMD压力可能还是不够,所以找了另一个压力奇大无比的算例——LiH-HFX。这个算例对机器的CPU性能、内存性能和内存容量都有很大的需求,是专门给超算做的,通常在超算上用成千上万核来跑,但这次我们用他来压榨双路9754和双路9654。
值得一提的是,像CP2K这样的MPI+OpenMP混合并行软件,需要针对不同的硬件配置做非常仔细的调优才能实现最大的性能。下图展示了经过调优后的并行参数。
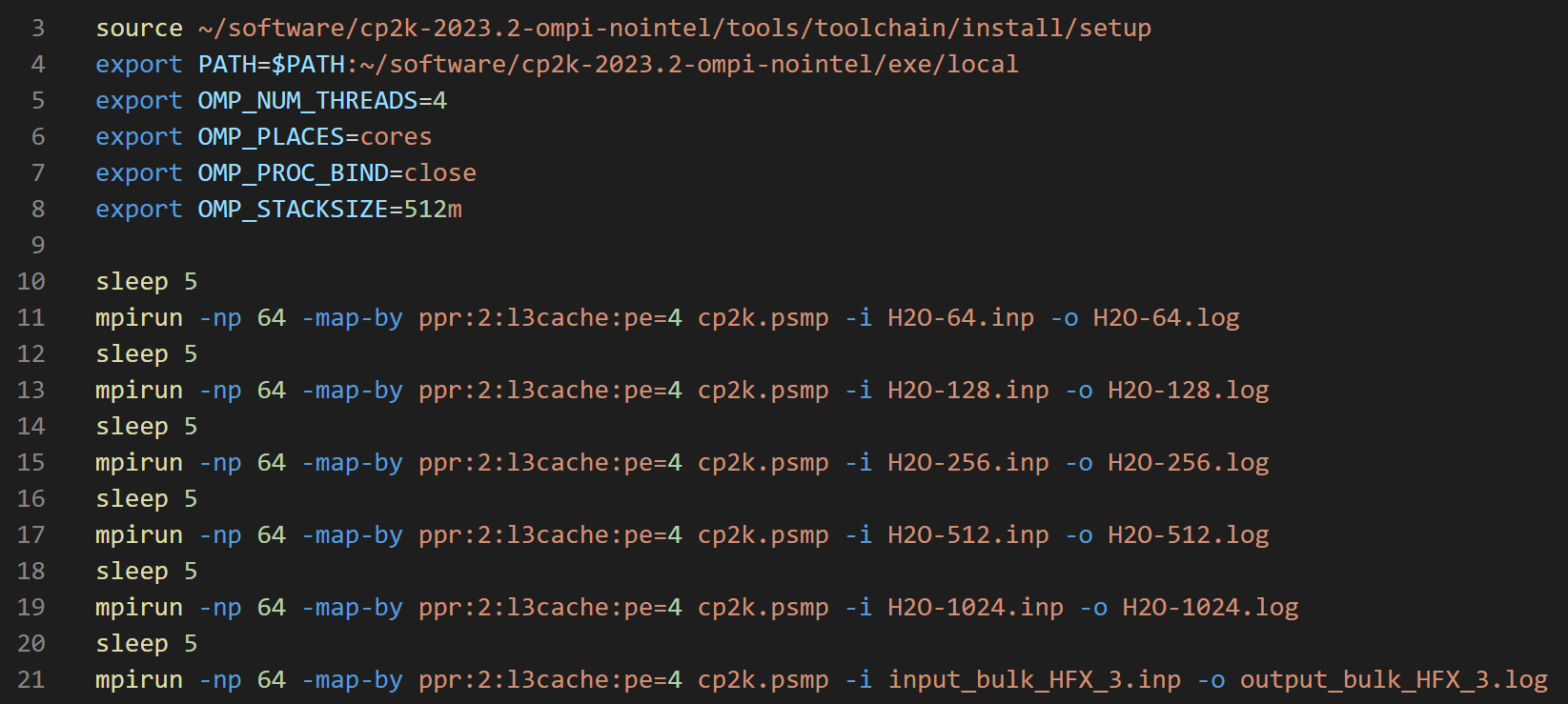 CP2K并行参数调优:双路9754
CP2K并行参数调优:双路9754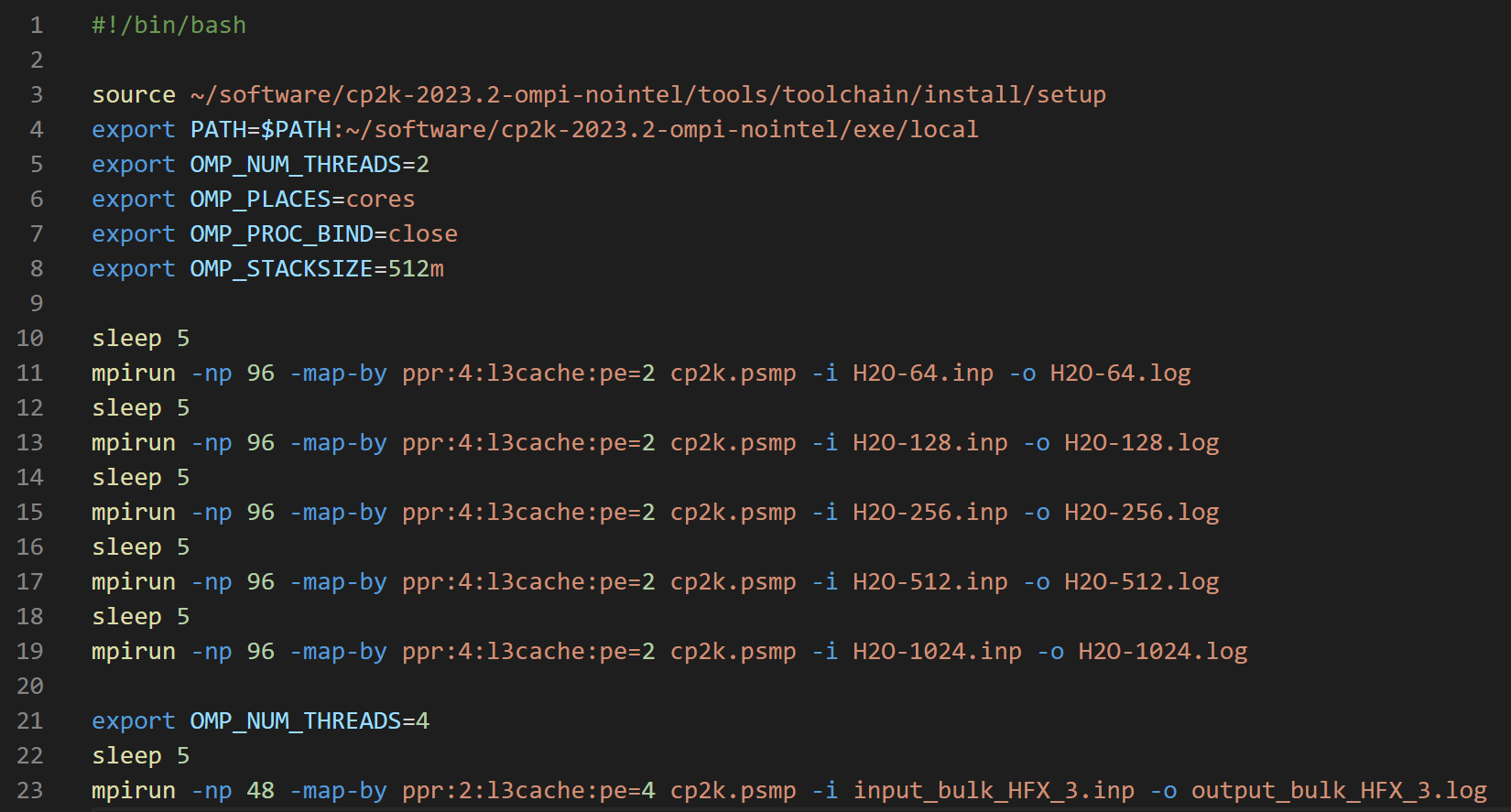 CP2K并行参数调优:双路9654
CP2K并行参数调优:双路9654VASP也是个著名的第一性原理计算软件。我们找来了英国超算用的benchmark算例,一个是二氧化钛晶体、纯泛函方法,另一个是碲化镉晶体、杂化泛函方法。其中纯泛函方法是VASP里最主流的计算方法;而坊间传闻,VASP的GPU版跑杂化泛函计算的加速比不错。
说到GPU,确实值得一测,就拿4090、RTX 6000 Ada,还有双精度超强的过气卡皇TITAN V来试试。
CP2K官方称CP2K的GPU版只支持A100、V100、MI250等计算卡。TITAN V的核心就是V100的核心,所以可以直接用官方脚本预设的V100选项;至于4090和6000 Ada,不试一下怎么知道它们能不能跑呢?众所周知,Ada架构相较于Ampere架构改动很小,SM编号都是8开头,所以就编译A100的版本,直接在4090上跑,发现还真能跑!又尝试修改编译脚本来启用Ada架构的flag(SM89),但实测发现速度还不如直接用脚本预置的A100或V100选项。
至于VASP,官方明确说了支持各种N卡,所以直接拿NVIDIA HPC SDK编译一下就能跑。
2.2 测试结果
2.2.1 CP2K
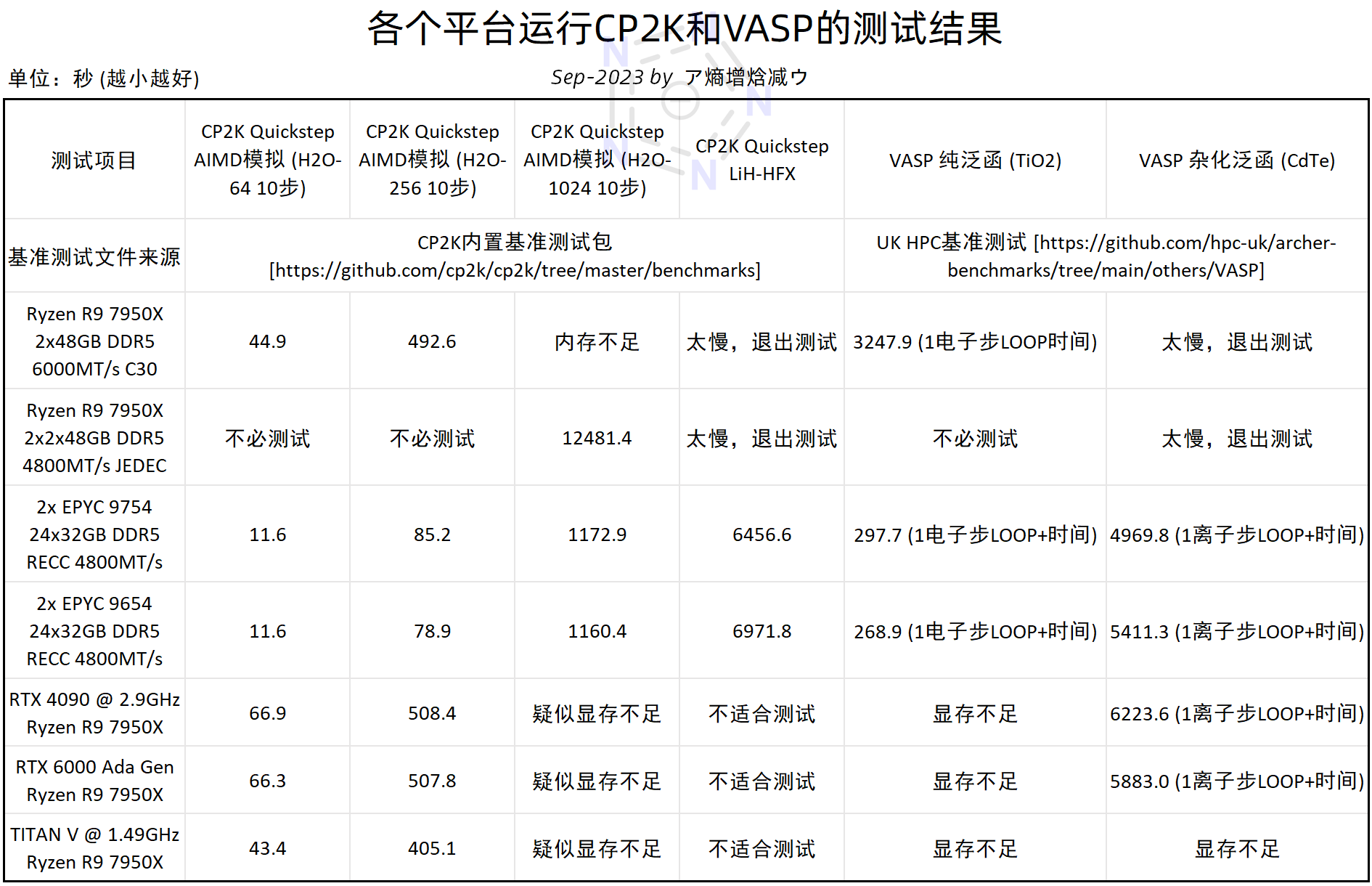
双路9754和双路9654全都顺利跑了下来,而7950X这边在跑1024个水的时候由于内存不足,直接报错退出了,把内存加到192G,终于勉强跑了下来,虽然速度实在是有点慢,只有双路9754/9654的不到十分之一。
再来看看GPU。4090和6000 Ada的速度几乎相等,比7950X还要慢一截,TITAN V双精度强,但是也就比7950X快了20-30%,看来CP2K的GPU加速比还是不太行。测试发现,H2O-1024在RTX 4090、RTX 6000 Ada和TITAN V上都无法运行,从报错信息来看疑似显存不足,但奇怪的是报错的时候nvidia-smi dmon监视工具显示显存远未被占满。
至于LiH-HFX,就不勉强可怜的7950X和那些单个GPU了,毕竟是专门给9654和9754准备的。测试运行过程中双路9754/9654功耗全程维持在800W,9754频率3GHz,9654频率3.6GHz,768GB内存几乎被耗尽,看着特别爽。最终双路9754和双路9654分别花了6456.6秒、6971.8秒跑完测试,速度和在2009年的超算上调用1024核相当。当然,超算的核数可不止1024个,多调用一些节点,双路9754/9654还是被轻松碾压了。
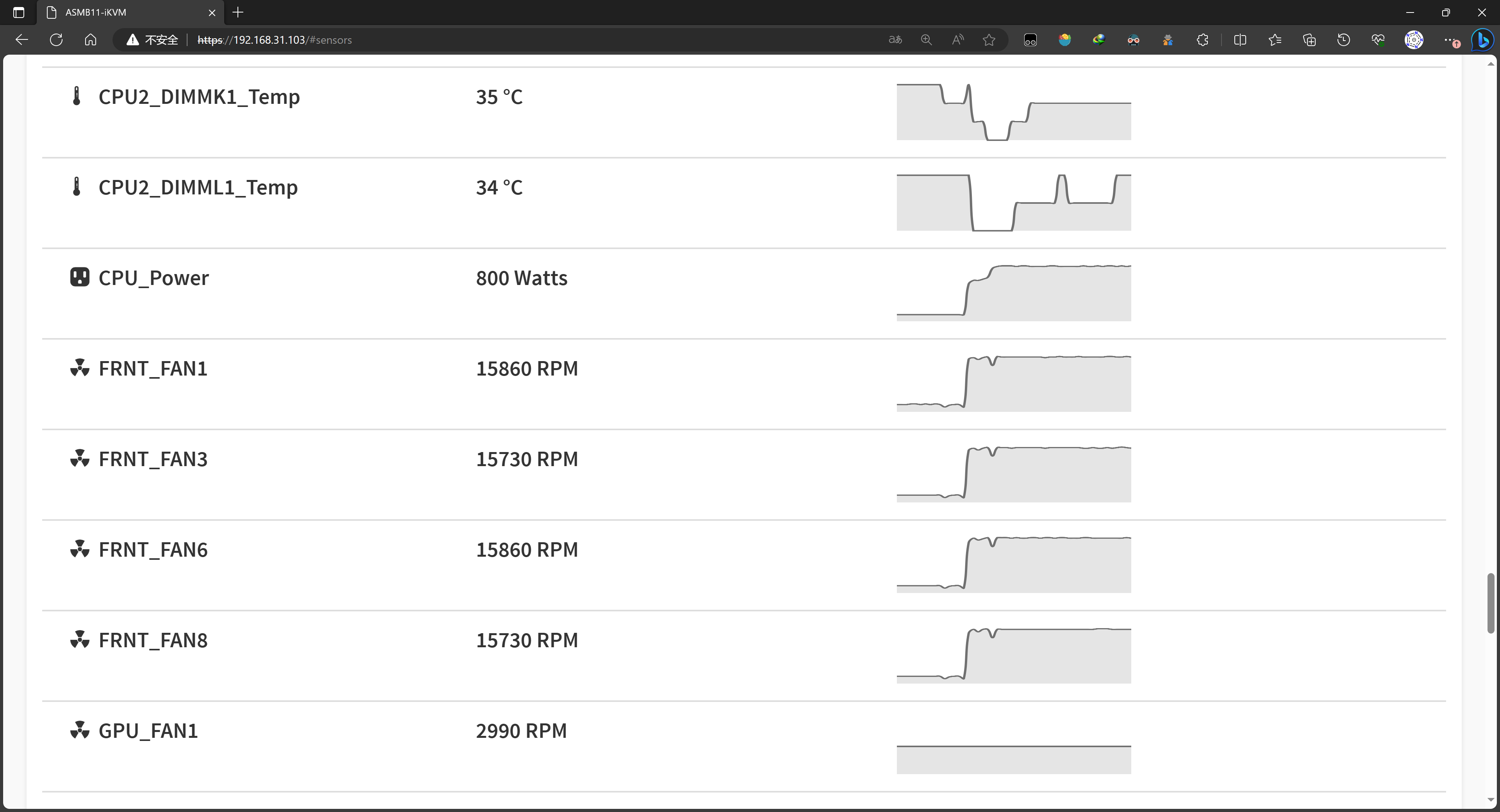 BMC数据
BMC数据 双路9754:800W @ 3GHz
双路9754:800W @ 3GHz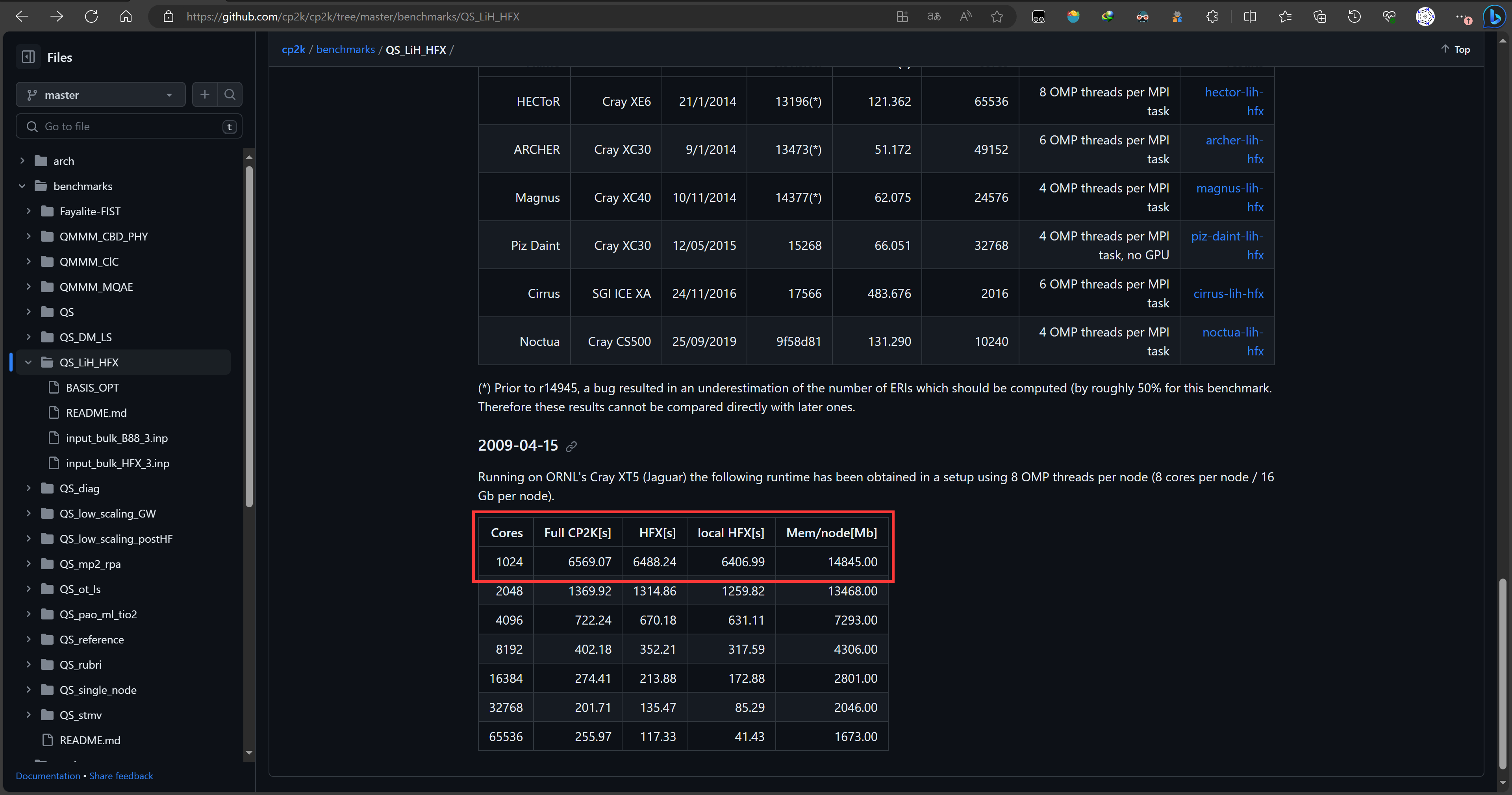 和超算比比
和超算比比顺带一提,OpenBenchmarking网站也有双路9654和双路9754跑H2O-64的测试结果,都是20秒左右,比本文的11.6秒差太多了,这显然是没有做好调优的后果。
2.2.2 VASP
为了能和7950X对比,二氧化钛晶体只跑1个电子步,最终结果双路9754和双路9654速度都是7950X的将近11倍,而GPU们全部因为显存不足而没法跑。
再来看看杂化泛函的测试。4090和6000Ada的速度确实挺不错,虽然依旧没打过双路9754/9654,但是已经比较接近了,至少没出现CP2K那样的差距。当然,TITAN V因为显存只有12G,还是没把这个测试跑下来。
本次测试也对VASP并行参数做了调优,使双路AMD EPYC 9654的性能达到了双路Intel Xeon 8383C(8380超频定制版)的2.76倍,推翻了以往关于“VASP在Intel平台有特殊加成”的“经验”。由于细节众多,且核心工作并非由我完成,故本次不做讨论,欢迎持续关注。
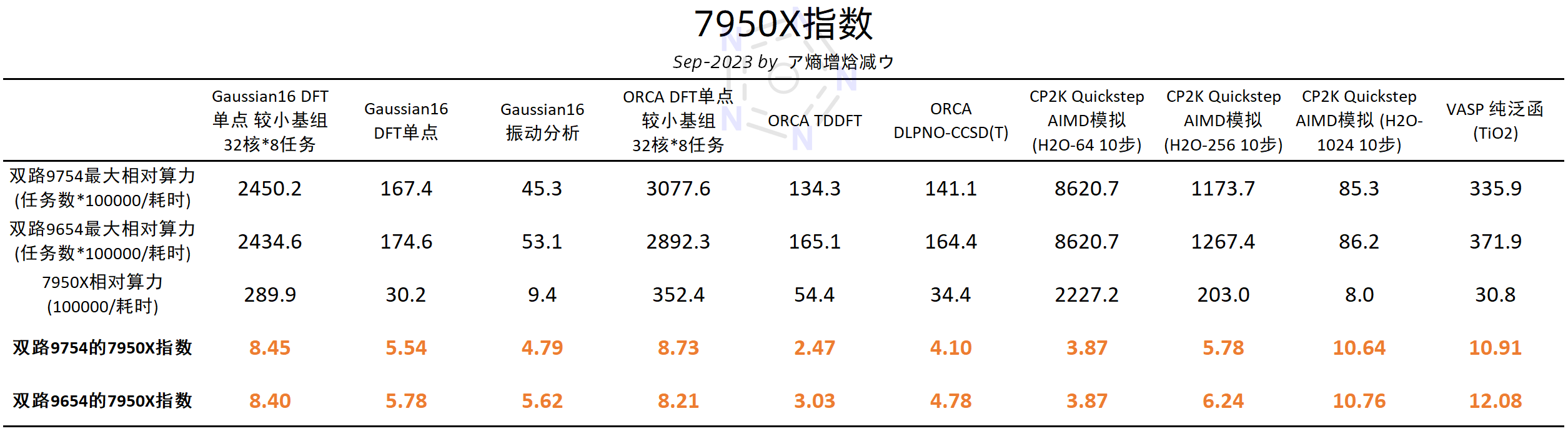
3 7950X指数
最后,我们把7950X能跑下来的一些算例做成了“7950X指数”,来衡量双路9754和双路9654分别相当于多少颗7950X。
文章评论