基于自己开发的服务器搭建的这套GPU集群已经在自己课题组里上线运行了一段时间(硬件如p4~9所示),跨节点并行计算性能完全符合预期,同时很稳定,至今从未出现过“掉卡”问题,比一些基于“大厂准系统”的8卡4090机器稳定多了。
目前只上了3个计算节点,24块V100 SXM2 16GB,还不是“完全体”,主要原因是机房capacity不足(白嫖机房还要啥自行车),等几个月后学校的新机房建成,也许有机会进一步扩展。
“完全体”有3种规模,架构分别如p1~3所示。其中p2的144-GPU配置是最理想的状态——从架构上来说,平衡了集群规模和通信效率;从实施来说,刚好用满3个2x10kW容量的标准机柜;从成本来说,IB连接线可以全部采用廉价的DAC铜缆。对于大多数搞科学计算研究的实验室来说,有一套由144块V100组成的、架构类似于初代NVIDIA DGX SuperPOD(核心特性是GPU-Direct RDMA)的、支持全机组高效并行的GPU集群,就可以做“很多事情”了。
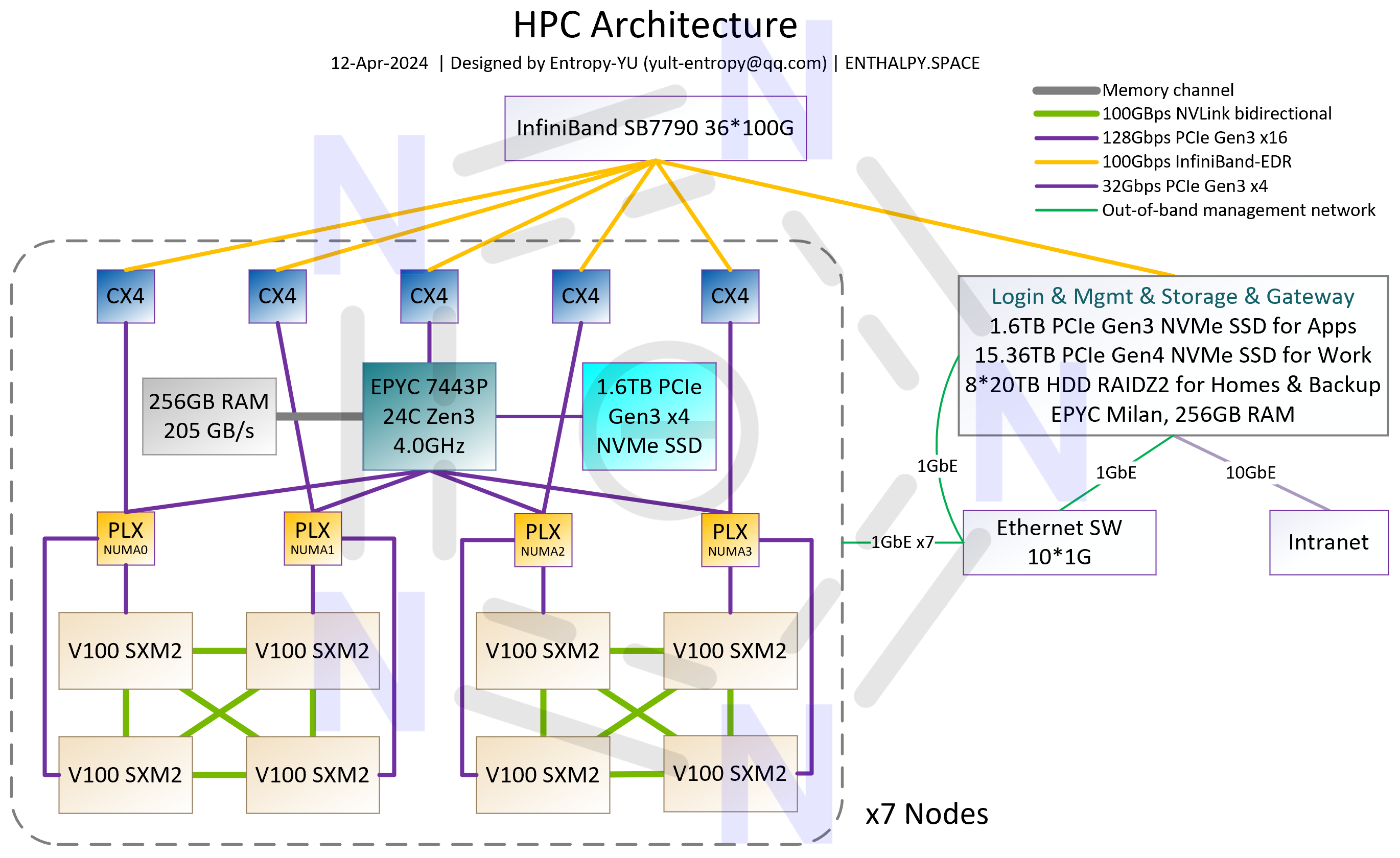
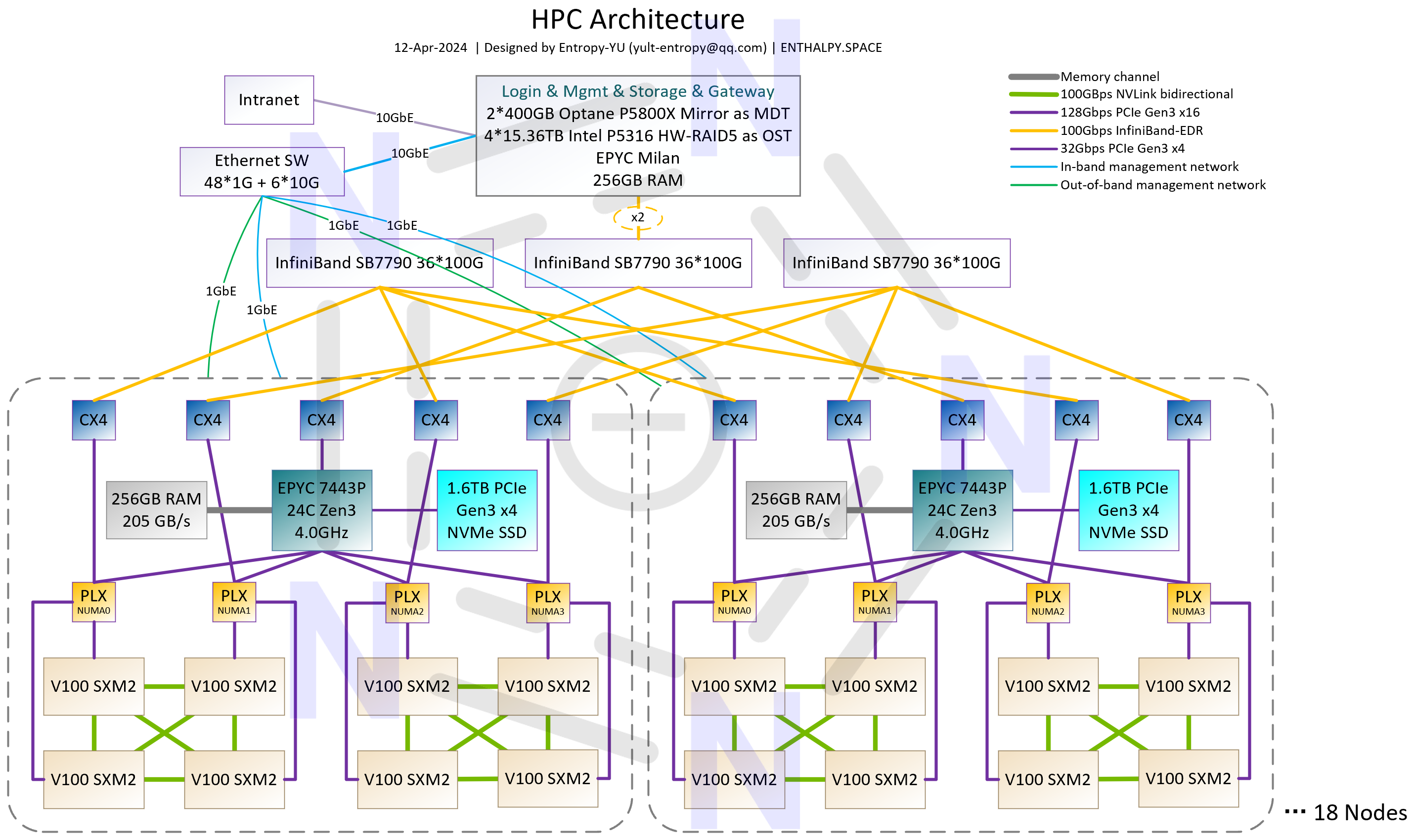
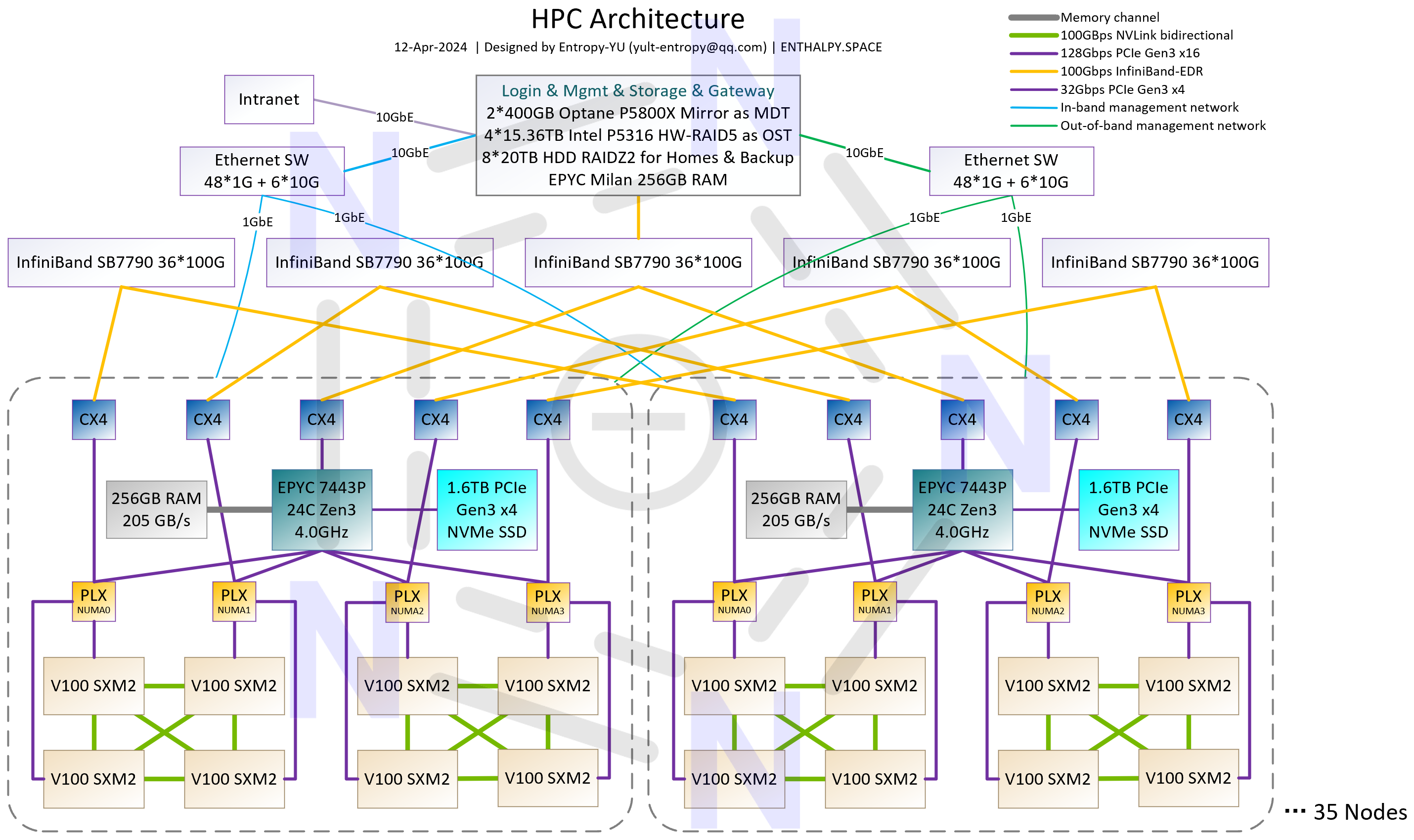
这套集群中,CPU、GPU、IB HCA、IB交换机、IB DAC铜缆都是二手的,计算节点是由我“二次开发”的,有大量的定制配件。所有硬件都是公费采购,计算节点每台4万CNY,IB交换机每台8000CNY,IB DAC铜缆根据长度从70~280CNY不等。144-GPU的“理想配置”,不到80万CNY就能搞定,对于绝大多数科学计算和 #AI4S 应用,性能都可以达到一台HGX-H100-8GPU服务器的3-4倍,而后者目前的单价超过250万CNY;也就是说,此方案在硬件层面的性价比是H100的10倍以上。






硬件细节和具体应用场景下case-by-case的测试以后有空再发文细说。几个月前就想发文讨论GPU加速在第一性原理计算以及一些AI4S应用中的实际性能,顺便介绍我自己二次开发的服务器,但是由于各种原因一直推迟,不同平台的benchmark数据倒是积累了快1000条了……
文章评论
8卡机箱也是自己设计的吗 厉害!
@蘑菇小象 是
以前在黄鱼上看过这个方案,武汉的一家,原来是抄袭您的方案啊
@蘑菇小象 市面上有2个定制的8-GPU方案,原始设计都是我的。武汉那家是我持续跟进的方案,不算抄袭,不过他们巨幅加价的行为我是完全反对的。DIY一套完全相同的配置只要3万,他们卖出来近6万。目前我们实验室是用半DIY的方式采购,7个计算节点(不算周边设施)平均单价3.75万。
@Entropy 嗯,这个机箱设计的非常棒,里面的风道设计和线路布局看着真舒服。年初那会我看过 有个欧雅图的也搞了一种四卡和八卡的,感觉和您这个很相似,现在知道了,原来本源是您的方案。。。。武汉那家的价格高的离谱,最可恨是那群屯板子卖高价的,我买那会也就1500块,现在基本看不到这个板子了,要不就是价格高的离谱。
我想问下,这玩意儿声音大吗?放课题室里是不是直接吵死人
@何日嘿嘿 噪音与环境温度强相关,8-GPU版本如果彻底满载(3.25kW),即使环境温度低于20℃,噪音也会达到不适合放在办公室的水平。另外,办公室的供电很难支持这样的机器。我目前只实施过一例办公室部署,是给朋友课题组部署的4-GPU版本,噪音和普通台式机差不多,GPU满载温度低于65℃。
HPC用的是那个软件啊,是lustre.还是GPFS啊
@夏天 如果你指的是存储,那么是BeeGFS。调度器是Slurm,以GPU为中心调度,实现GPU-NUMA Affinity