近两年以纯玩乐心态捣鼓了不少大大小小的HPC项目,亲自设计和搭建的HPC也有许多套,在此挑选近半年内由我全栈完成的3套小型HPC来写点杂谈,顺便对HPC/AI Infra行业现状发表一些意识流评论。
P1-4
我自己所在实验室的GPU集群,共7个计算节点(单节点配置参考去年夏天的贴子:手搓高性价比GPU集群),平均造价~¥3.8万。这是V100 UltraPOD 1296超级计算机的原型机,在科学计算和AI-for-Science应用中相较于DGX SuperPOD H100实现了20倍性价比提升。
48-GPU并行规模下,完成10万原子体系的1μs量子力学精度分子动力学模拟,只需3个星期;56-GPU并行规模下,完成1100万原子体系的1ns量子力学精度分子动力学模拟,只需28小时。我们的PI曾在朋友圈对此做过简单宣传。
BTW,前面提到的1296-GPU的完整紧耦合系统已于去年底完成所有设计和大部分验证,架构十分有趣且大胆,可惜实验室内部暂无落地的经济实力——虽说性价比提升了20倍,但那只是相较于造价¥1.2亿的DGX SuperPOD方案而言。不过,即使如此,也非常感激对我彻底“放养”的PI以及其余情同手足的伙伴们给我折腾的空间。
图片均已发布在实验室网站上(Resource - LIU's lab)。请忽略P1中画出的其他分区。把35条手指粗的IB铜缆整理成这样基本已经尽力,光缆能不用就不用——光模块昂贵、延迟高、故障率高、发热大,除了传输距离远、抗干扰以外一无是处。
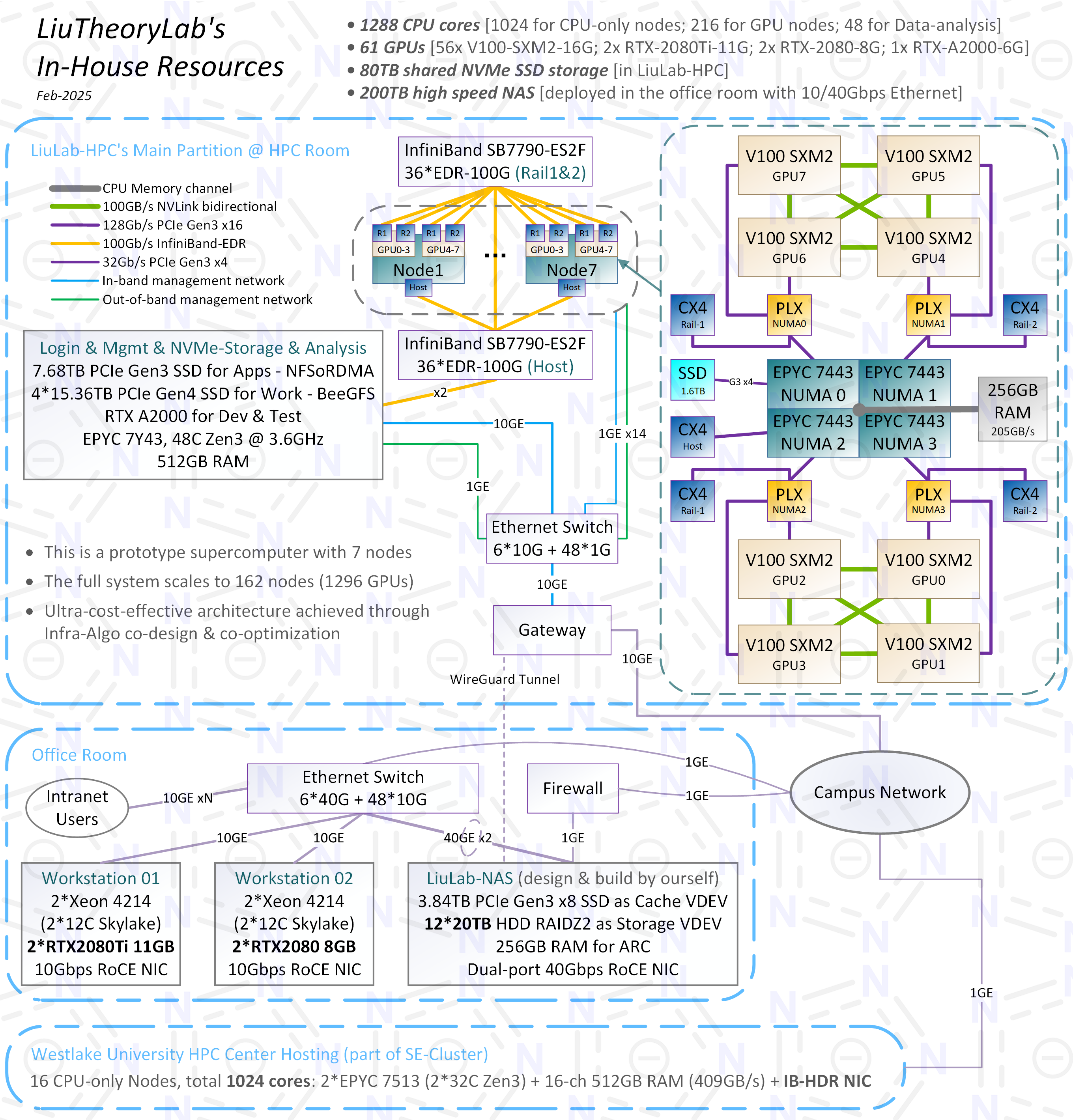 ▲P1. 架构图(请忽略其他分区)
▲P1. 架构图(请忽略其他分区)
 ▲P2. Full-View
▲P2. Full-View
 ▲P3. Compute Nodes Group - Front (Air Inlet)
▲P3. Compute Nodes Group - Front (Air Inlet)
 ▲P4. Head-Node Inside
▲P4. Head-Node Inside
P5
为某不便透露名称的算力租赁商搭建的GPU集群,包含160块AMD Instinct MI100,Dual-Rail架构组网。无法公布实体照片,因为甲方不允许(非常奇怪的甲方)。配件选型不是我做的,因此并非最佳配置,其中CPU严重拖后腿,性能全靠组网优化。此外,存储最终也未实现架构图中的配置,不知我放手后他们是怎么搞的。我只知道他们绕一大圈找了我的朋友来接手维护……
整机组并行,对1亿原子体系进行量子力学精度的分子动力学模拟,速度为0.3 ns/day,接近2020年戈登贝尔奖的项目(后者使用了整台Summit超级计算机的27648块V100)。
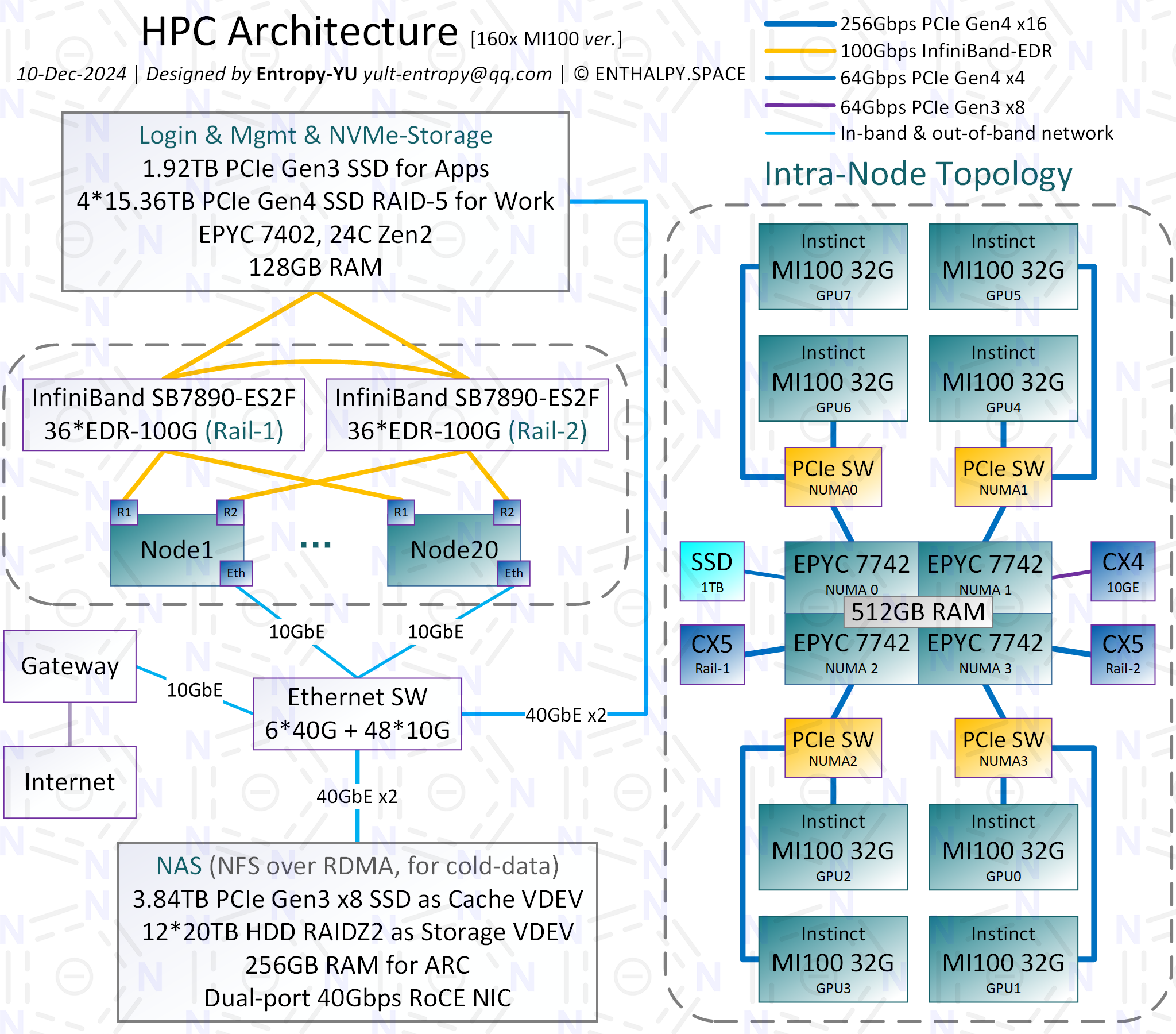 ▲P5. 架构图
▲P5. 架构图
P6
为某三甲医院生物信息学团队搭建的生信集群,计算节点是8台双路9654 + 1.5T RAM,每颗CPU配1块CX4 EDR IB网卡,一体式“半液冷”(机箱内置冷排)。关键在于存储系统。主存储采用OpenZFS (后端MDS和OSS) + BeeGFS (前端分布式并行文件系统),启用透明压缩,使不到1PB的存储空间可以当作~3PB来使用(在用户实际应用场景下压缩率为~3倍),实测峰值写入>10GB/s,峰值读取>20GB/s。利用计算节点的7.68TB PCIe Gen5 SSD实现burst-buffer,可以组成61TB的缓冲存储池,实测峰值写入>55GB/s,峰值读取>80GB/s。
吐槽:此前我从未玩过生信,此次才切身体会到口耳相传的“生信低效代码”是怎么回事…简单而言就是毫无并行化,我这种计算机门外汉用本科时通过传统搜索引擎学到的技术稍加优化就能实现十几倍速度提升…
虽然不太会玩生信,但可以跑点老本行。顺手测试了CP2K 2025.1,6节点并行(1152核),MPI 576 * OMP 2,Slurm调度,自动绑核,H2O-4096体系MD模拟速度9~11 min/step,首个SCF步518s,后续SCF步77s,各节点IB网卡峰值流量为单向2*25 Gbps;LiH-HFX体系(杂化泛函)首个SCF步268s,后续SCF步27s,各节点IB网卡峰值流量为单向2*3 Gbps。
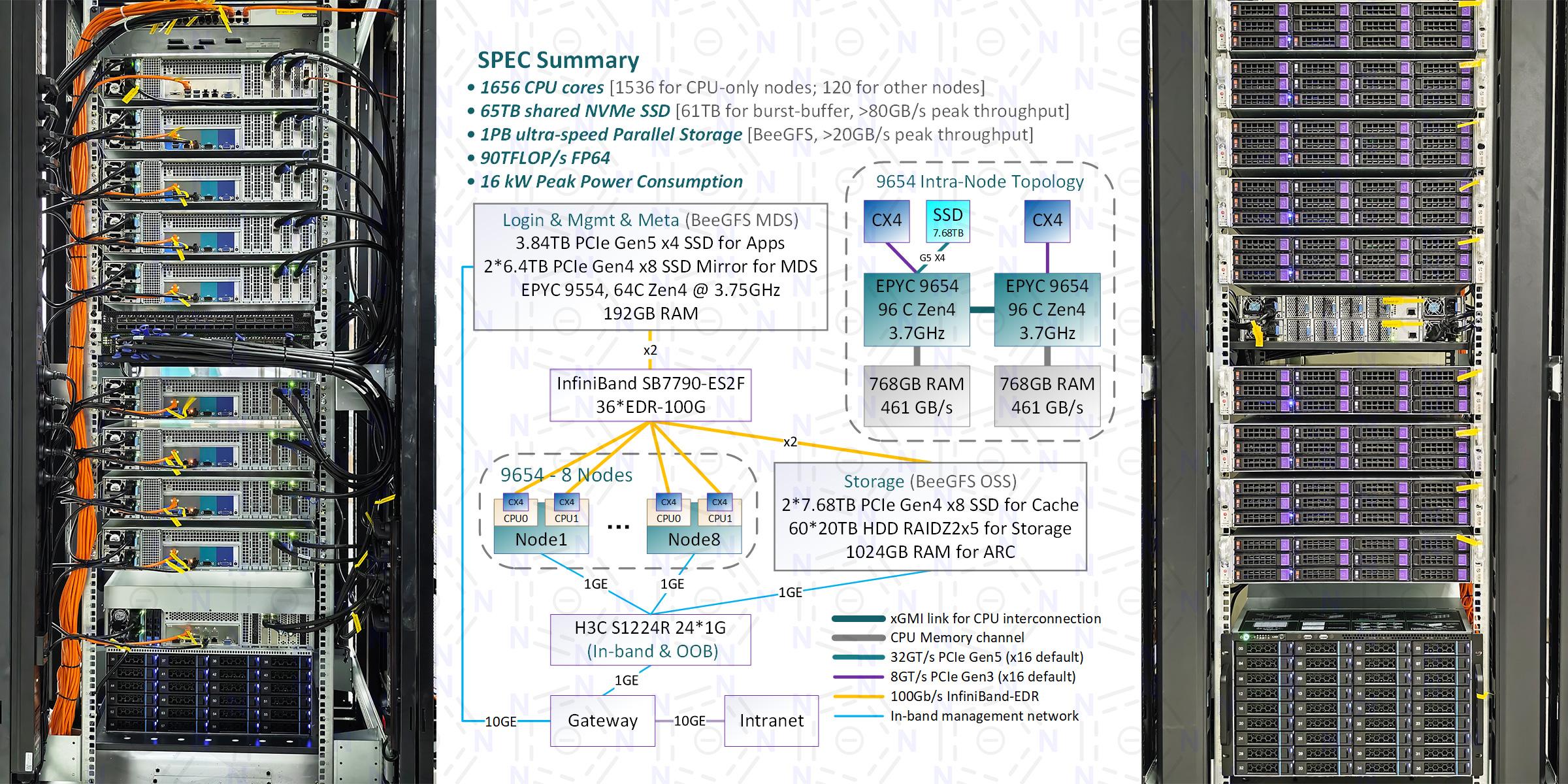 ▲P6. 架构图&实物照片
▲P6. 架构图&实物照片
P7
年初DeepSeek爆火后在组会上做的小讨论,包含我当前对于HPC/AI Infra建设的主要观点。
 ▲P7. 组会PPT
▲P7. 组会PPT
补充两条锐评。
- 如今一提到“本地部署DeepSeek-R1满血版”,动辄百万预算起步,非常可笑、可悲。且不提KTransformers等个人/迷你团队方案只需几千~几万元,即使是中大型组织,要求上百并发、数千token/s的Decoding速度,硬件造价也只需要~¥30万。再讲究一点,实施PD分离+EP,降低首token延迟的同时把Decoding吞吐量推到上万,¥50万以内也能搞定了。被硬件vendor们洗脑真的很可悲。
- 服务器芯片的“体质”差异可能比消费级芯片还要大。相同型号、相同OPN、相同批次的芯片,在相同负载下的频率,两极差异高达10%甚至更多,这对HPC来说真是要了命了。个人经验是制程越先进,频率差异问题越严重。V100的两极差异不到7%,且低频率芯片出现概率也不高;A100、MI100的两极差异则有8~10%;EPYC 9654超过10%;至于H100 SXM5,虽然我未曾较大规模地折腾过,但坊间广为流传的“10%故障率”足以说明一切。
文章评论
P1里边的1024 CPU cores是那一部分的呀,好像没看明白
看到了,原来是另一台的