作为科学计算研究人员,站在HPC/科学计算的角度评论一下昨天发布的Blackwell GPU。
1. 完全没提到Vector算力,包括FP32 Vector和FP64 Vector。而这两者是HPC最主要使用的算力,由所谓的CUDA Core提供。FP64 Tensor算力相较于上代H100也倒退了,64TFLOPS>40TFLOPS,另外,作为对比,AMD Instinct MI300X的FP64 Matrix是163TFLOPS。NVIDIA放弃HPC是意料之中的事情,然而产品宣传中还在提HPC,HPC性能却“倒退”,这种行为实属恶臭。
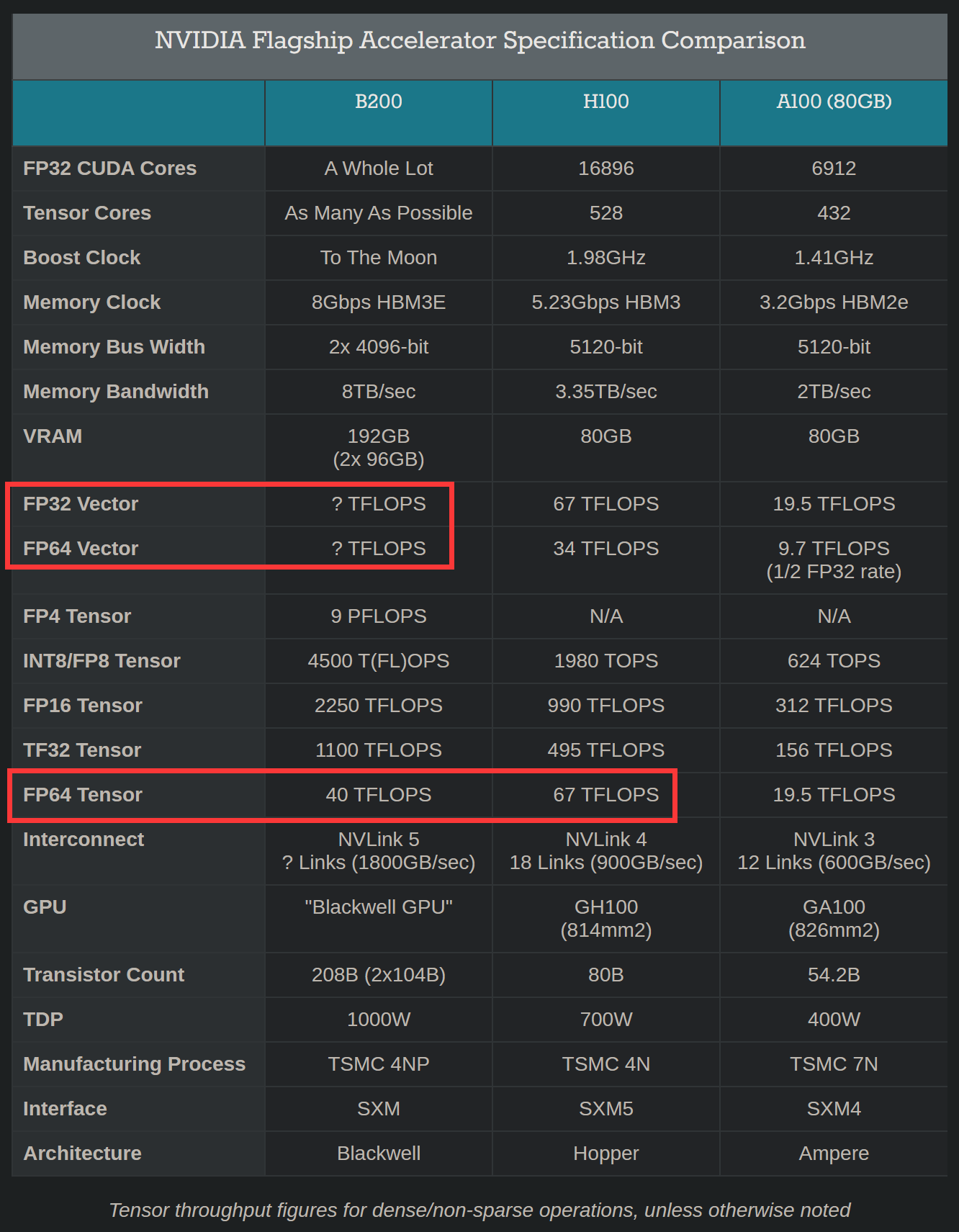
2. 虽然不知道B100/B200的FP32 Vector和FP64 Vector算力,但可以大胆预测这东西用于HPC/科学计算不可能有性价比。当然,H100/H200也半斤八两,B100/B200只是会更臭罢了。建议科学计算用户去捡大船V100 SXM2用,这玩意性价比可太高了,美国数据中心下架的货只要30美元一片(不过最近被国内某些只要钱不要母亲的奸商炒到了接近2000CNY,建议不要让奸商尝到甜头)。
3. 可以预见的是,下一代会彻底把Vector算力(CUDA Core)和Tensor算力(Tensor Core)解耦,出现“纯Tensor Core”芯片专门服务于AI,这种芯片将不再适合被称为“GPU”,而应称为NPU/TPU,这种芯片完全无法用于HPC。另一方面,届时的Vector-oriented SKU性能会如何就很悬了,毕竟如今HPC的市场还不到AI的1成,HPC产品要怎么做全凭黄狗良心,就像游戏GPU一样。
4. 唬人的算力指数上升,有很大一部分功劳是每代推进一次的“降精度”,如今已经降到FP4,每个参数只有2^4=16种状态,几乎不可能继续降低精度,降精度红利已经消失,好奇之后NVIDIA打算怎么办。大概率是继续堆interconnection,建造规模更大的“Single Giant GPU”和“AI Factory”。
5. GB200 Super Chip的架构梦回IBM Power 8 + P100和IBM Power 9 + V100……果然那个男人还是忘不了她……

文章评论
一针见血的