Aug-2023 by ア熵增焓减ウ | yult-entropy@qq.com | entropylt@163.com
It's everyone's duty to squash the green behemoth.
0 Introduction
In the past two years, numerous world-leading supercomputers have embraced AMD GPUs as heterogeneous accelerators. As a result, many high-performance computing (HPC) applications have begun adapting to the ROCm software stack, with a significant portion achieving advanced stages of development and delivering impressive performance. These applications can now be effectively utilized for formal scientific research purposes. Additionally, certain applications offer native support for Intel GPUs.
With this in mind, I undertook a comprehensive series of molecular dynamics (MD) performance benchmarks encompassing all NVIDIA Ada Lovelace desktop GPUs, as well as top-end consumer AMD GPUs released within the last five years. Furthermore, I included Intel's current top-end consumer GPU, the ARC A770, in my tests.
Some applications have supported GPUs from various vendors using OpenCL for many years. However, OpenCL has proven to be inefficient, and its actual performance falls short of being usable. As a result, mainstream GPU vendors have long abandoned the maintenance of OpenCL. In light of this, a more efficient and modern solution was adopted for this test.
The AMD Infinity Hub provides a comprehensive list of HPC and AI applications that are already compatible with AMD GPUs and ROCm software stack. However, the introductory information provided is quite superficial. To gain a thorough understanding of how to run these applications on AMD GPUs, it is advisable to carefully review the official documentation, manuals, Readme files, or respective application wikis. In this particular test, four molecular dynamics applications were tested: GROMACS, Amber, OpenMM, and LAMMPS. For detailed instructions on running these applications on AMD GPUs, please refer to "Switch to AMD [Part Ⅱ]".
When it comes to adapting AMD GPUs in these four applications, all except GROMACS have opted for the HIP approach. This involves directly utilizing the HIP programming model provided by AMD to achieve GPU acceleration capabilities similar to the CUDA platform. However, like CUDA, this approach also carries the limitation of code being specific to a particular vendor's GPU.
GROMACS takes a different approach compared to the other applications. Starting with version 2023, GROMACS has incorporated a new heterogeneous programming model called SYCL. This enables seamless migration between different computing hardware types from various vendors without the need to modify the source code. With the SYCL backend, GROMACS 2023 can now leverage all CUDA-supported acceleration features on any computing hardware with an available SYCL implementation. Importantly, this transition does not introduce any differences at the user application level compared to the native CUDA version. Consequently, the previous GROMACS experience and templates based on NVIDIA GPUs can be directly applied to these different hardware configurations.
"Computing hardware with an available SYCL implementation" encompasses LLVM-supported CPUs, AMD GPUs, Intel GPUs, NVIDIA GPUs, Hygon DCUs, and more. Additionally, it is worth mentioning that Moore Threads GPUs will also support SYCL in the future through an update to the MUSA Toolkit.
Furthermore, it is worth noting that the latest version of Kokkos, LAMMPS' GPU-accelerated module, offers preliminary support for the SYCL backend. This enables the compilation of Intel GPU-compatible Kokkos using Intel oneAPI DPC++. However, it should be mentioned that the Intel ARC A770 lacks double precision computing capability. As a result, the performance of LAMMPS Kokkos on the ARC A770 was not included in this test.
Lastly, it is important to clarify that this article does not provide a conclusive summary covering the entire text. Readers are encouraged to thoroughly read each part of the article, including every sentence, and extract the information that is most relevant to their needs.
1 Methods
Hardware details:

OS details:
Ubuntu 22.04.3 LTS, Linux 6.2.0-26-generic x86_64, GNU 11.4.0
GPU driver & toolchain:
- For AMD: AMD GPU driver version 6.1.5.50600-1609671, ROCm 5.4.6~5.6.0;
- For NVIDIA: NVIDIA GPU driver 535.86.05, CUDA Toolkit 11.8;
- For Intel: Intel GPU driver i915 release 4/21/2023, xpu-smi, Intel oneAPI Toolkits 2023.2 (Base Toolkit + HPC Toolkit)
Apps:
- GROMACS 2023.2 – OpenSYCL develop 25Jul2023 (AMD GPUs) / v0.9.4 (NVIDIA GPUs) - SYCL-based oneAPI DPC++ 2023.2 (intel GPU)
- Amber 22 - AmberTools 22 (AMD GPUs) / 23 (NVIDIA GPUs) – Amber 22 HIP Patch 3Jan2023 (AMD GPUs)
- OpenMM 8.0.0 – OpenMM HIP Plugin 8Mar2023 (AMD GPUs)
- LAMMPS 2Aug2023 – Kokkos 4.1.0 (AMD GPUs) / LAMMPS bundled (NVIDIA GPUs)
All 4 applications are built from source code, enabling optimizations targeting GPU architectures. Note that for GROMACS tests on NVIDIA GPUs, not only the CUDA version but also the OpenSYCL backend + CUDA runtime version was built.
Benchmark datasets:
The datasets used in the GROMACS, Amber, and LAMMPS tests are basically unchanged from the October 2022 tests. Some of my personal datasets were included in the GROMACS and Amber tests, as detailed in the October 2022 article. To ensure a fair comparison with OpenMM, additional models were added to the Amber datasets, although this particular aspect is not discussed in this article.
In the case of the LAMMPS dataset, the system sizes were modified based on the official configurations provided by LAMMPS. Specifically, each system was replicated in three dimensions to increase VRAM consumption to over 50%, aligning with the test results reported on NVIDIA's website.
For OpenMM, benchmark datasets from the official package bundle were utilized in this test.
All datasets used in this test, along with the corresponding benchmark scripts, can be downloaded from the link below.
Aliyun Drive: https://www.aliyundrive.com/s/5L35M77DCzA; Key: 8si3 (Self-extracting file with EXE format, double-click to extract)
Google Drive: https://drive.google.com/drive/folders/1pKfgHuk3eb0VZ-txbv03TMPCB8tFR_J- (PDF included)
2 Results and discussion
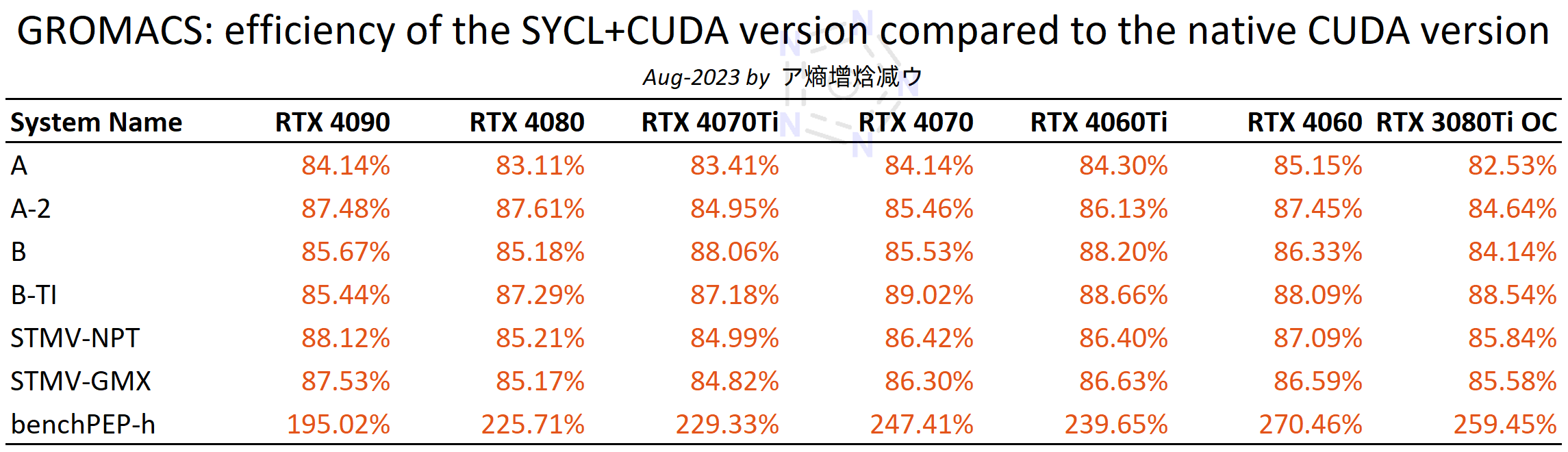
2.1 Efficiency of the SYCL+CUDA version of GROMACS on NVIDIA GPUs
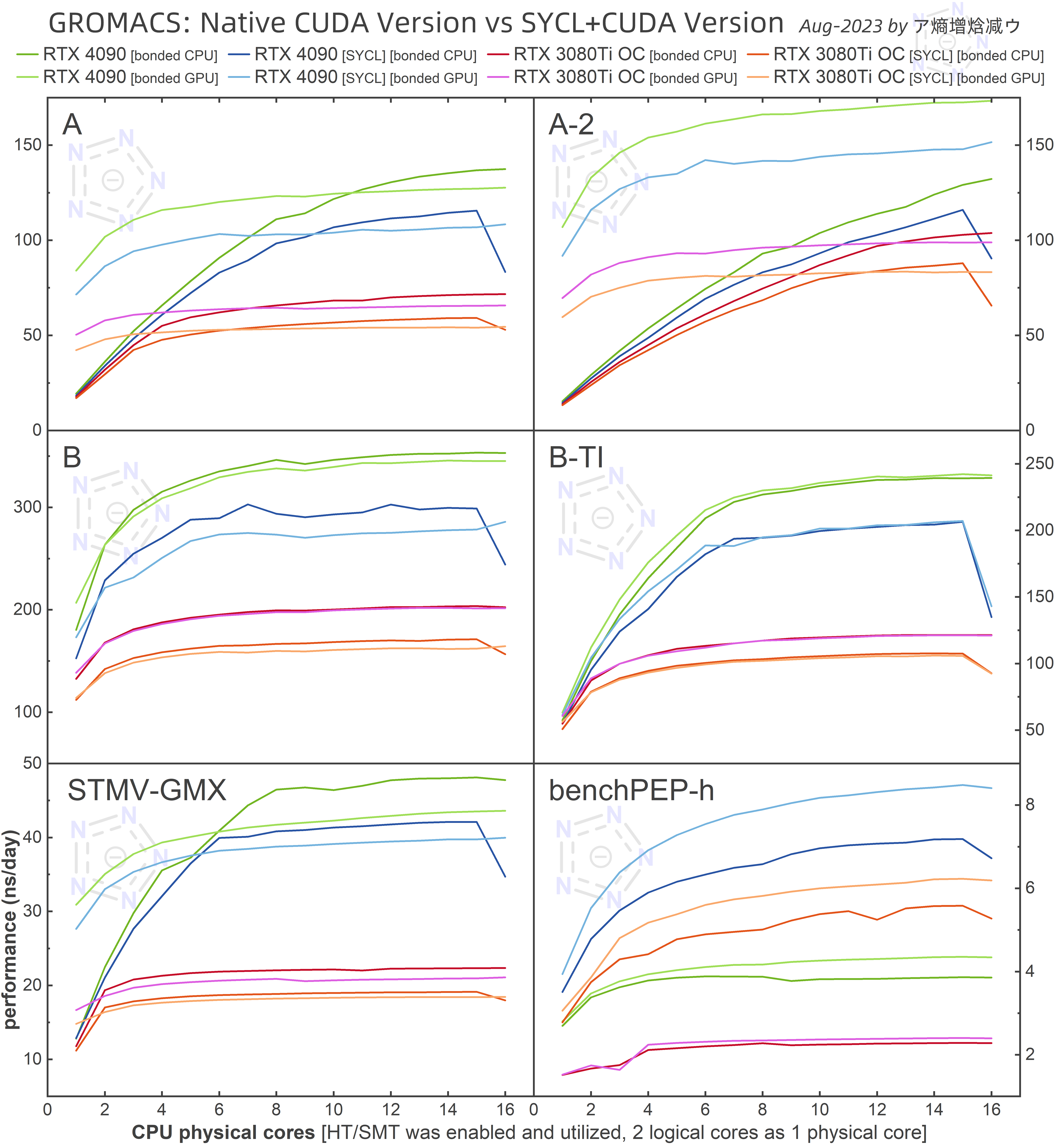
Compared to native CUDA versions, SYCL+CUDA versions generally suffer performance losses of 12-17%. However, it is worth noting that there is an intriguing observation for extremely large system, i.e., benchPEP-h, where the SYCL+CUDA version demonstrates remarkable acceleration. The performance-cores curves clearly illustrate that the SYCL backend introduces additional overhead, leading to a significant decline in performance once GROMACS exhausts the last CPU core within "bonded CPU" simulations.
2.2 Performance ranks
For GROMACS, Amber, and OpenMM, selecting the STMV system that could "squeeze" GPUs dry, and utilizing the original parameters without any modifications.
For LAMMPS, using the modified ReaxFF/C system as mentioned before.
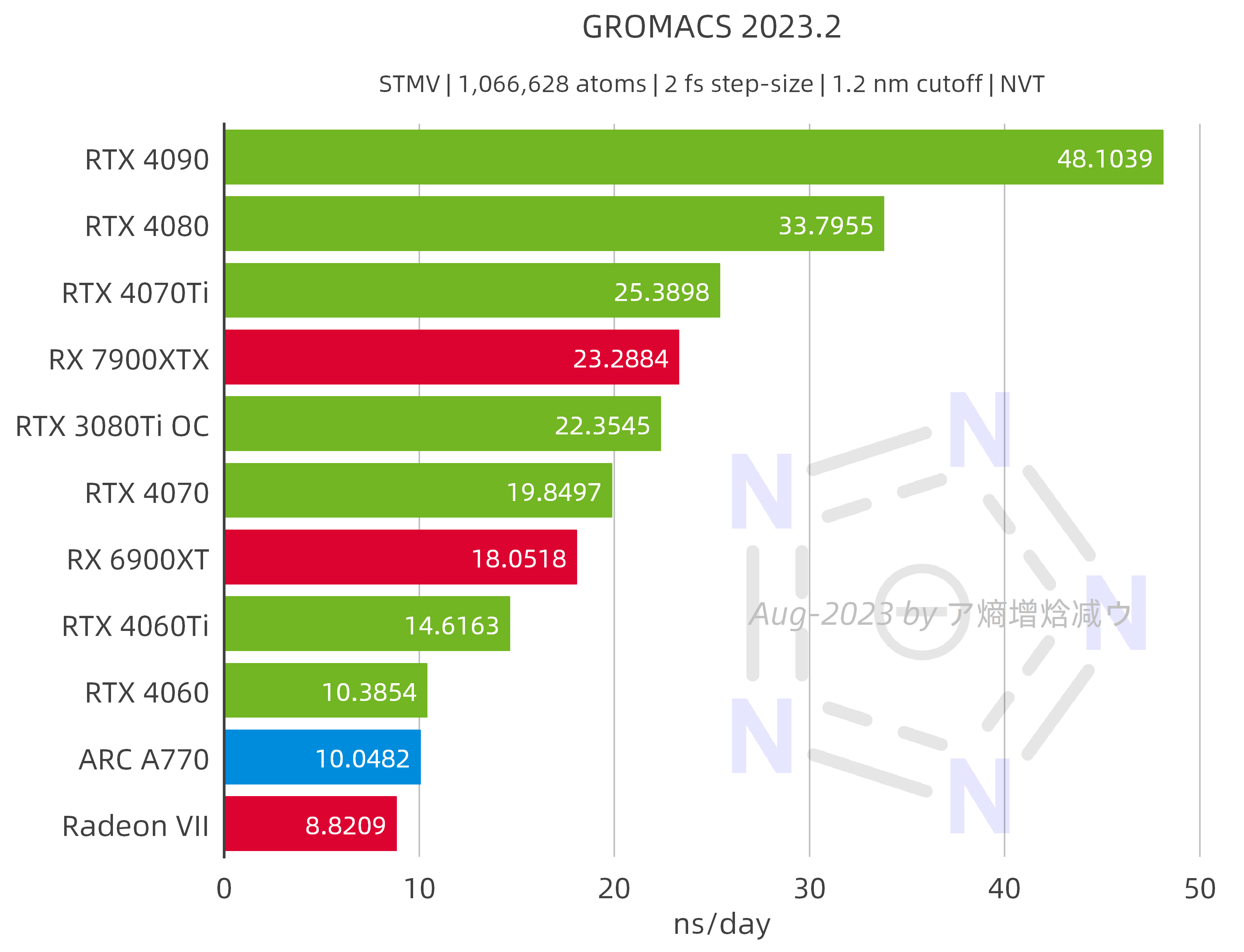
2.2.1 GROMACS 2023.2
The data used here is the maximum value obtained through scanning different core counts and different bonded options. It is important to note that the performance of AMD GPUs and Intel GPUs in GROMACS falls considerably short of their theoretical capabilities, which may be explained by the fact that the current SYCL backend is still inefficient. (28-Aug-2023 update: According to information provided by Szilárd, the core developer of GROMACS, this may not be an appropriate statement.)
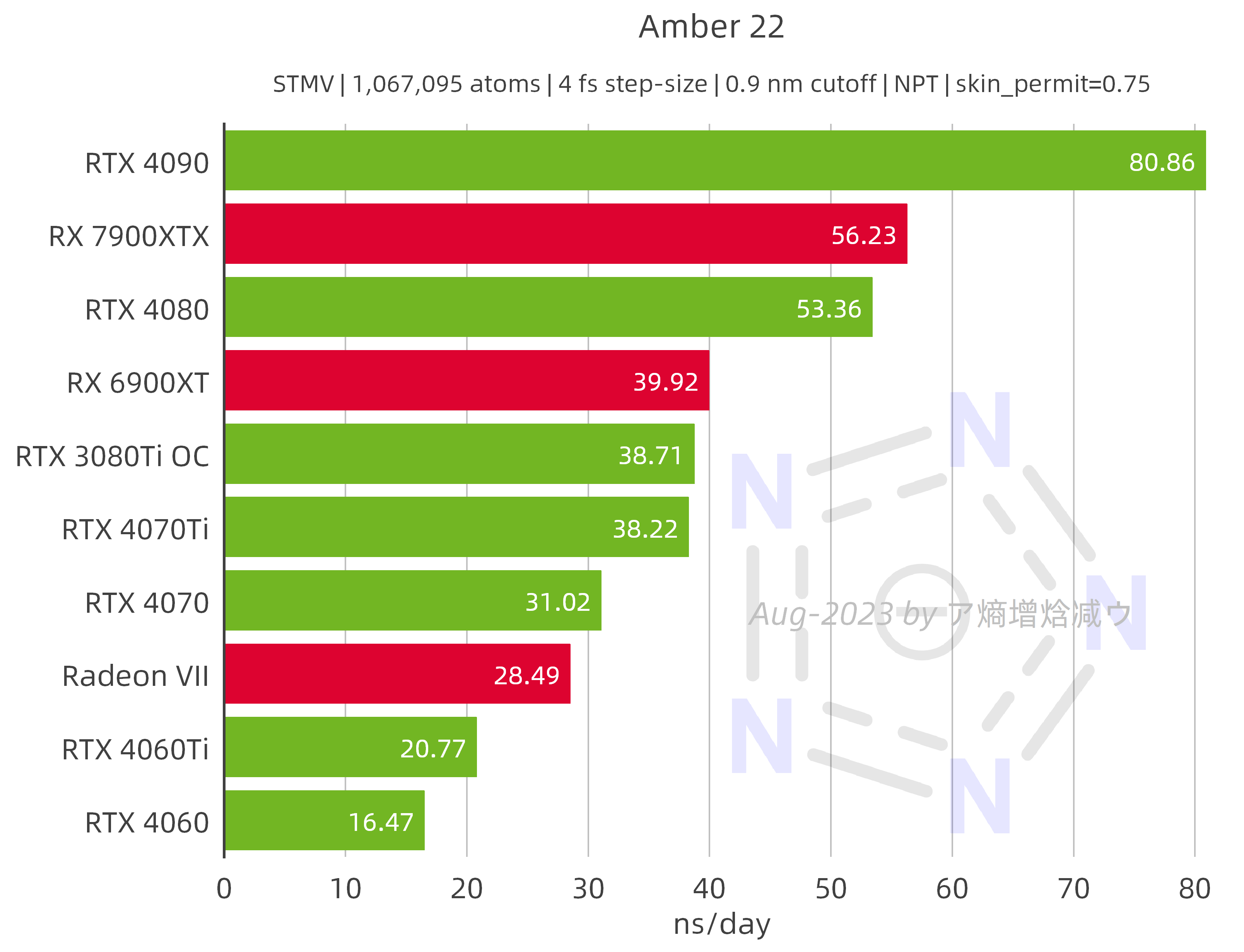
2.2.2 Amber 22
AMD GPUs performed according to expectations, with the RX 7900 XTX running 41% faster than the RX 6900 XT and 70% faster than the RTX 4090 on the STMV system. The Radeon Ⅶ is impressive: it achieves 92% of the RTX 4070 on the STMV system.
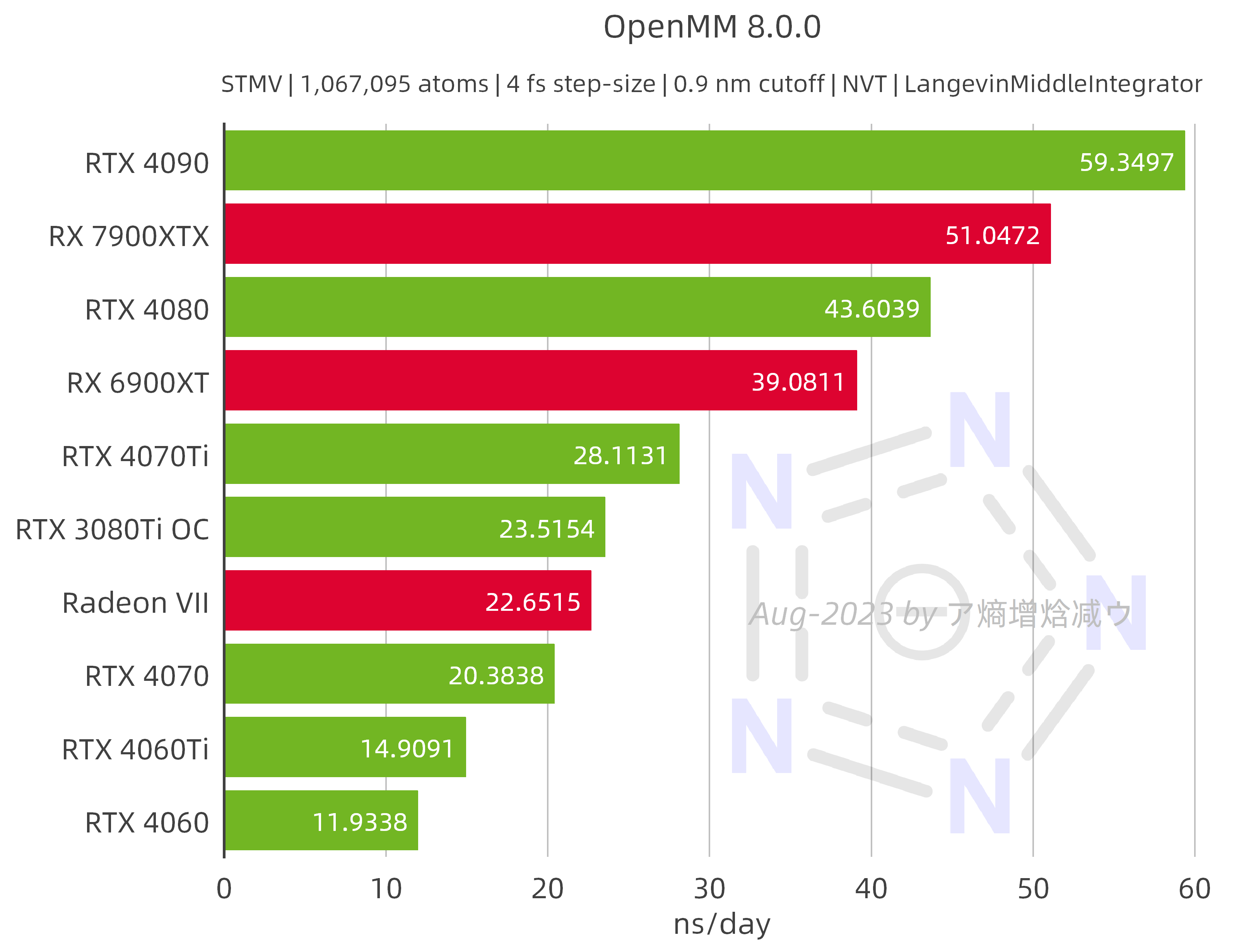
2.2.3 OpenMM 8.0.0
AMD GPUs perform very well on the STMV system. The 7900 XTX achieves 86% of the RTX 4090's performance, the 6900 XT achieves 90% of the RTX 4080's performance, while the Radeon Ⅶ almost tied the RTX 3080Ti / 3090, which is truly impressive.
Please note that some of the data from this test may be updated on the OpenMM website in the near future, with the RTX 4090 data already being updated. It is worth mentioning that another user has also conducted numerous performance tests on OpenMM-HIP, including running it on Windows using the newly released Windows HIP SDK. This user employed Sapphire Nitro+, which has a much higher TGP and boost clock frequency compared my MSI GAMING TRIO CLASSIC. As a result, it achieved a remarkable performance of 53.5723 ns/day on the STMV system, surpassing 90% of the RTX 4090's performance.
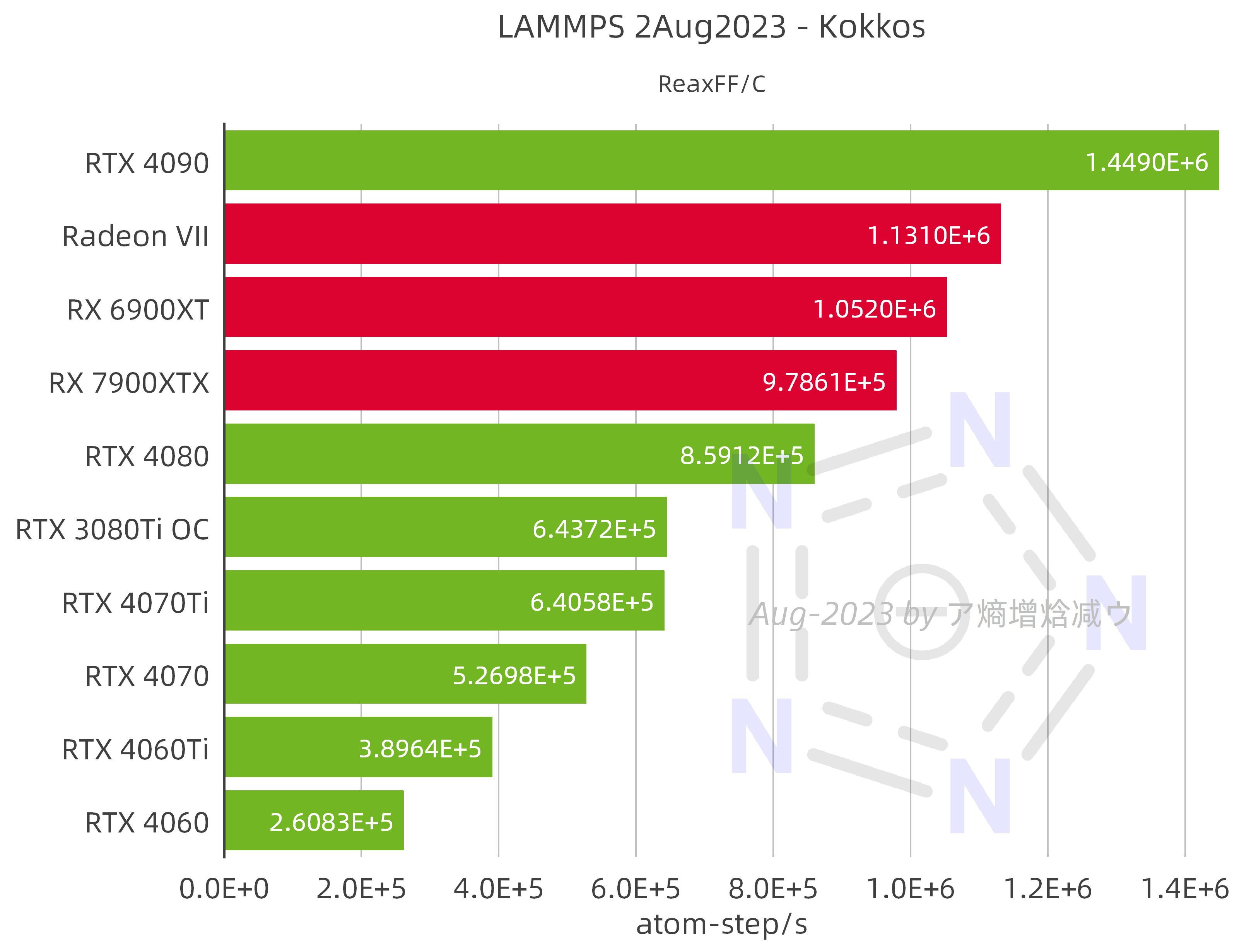
2.2.4 LAMMPS 2Aug2023 – Kokkos
With a peak FP64 performance of 3.36 TFLOPS, the AMD Radeon Ⅶ delivers impressive performance in ReaxFF simulations, surpassing the RTX 4080, RX 7900 XTX, and RX 6900 XT, and reaching 78% of the RTX 4090. In comparison to NVIDIA's results, the Radeon VII exhibits 35% of the performance of the V100 SXM. Interestingly, although the peak FP64 performance of the RX 7900 XTX is higher than that of the RX 6900 XT, the speed of ReaxFF simulations shows the opposite trend, which is quite surprising.
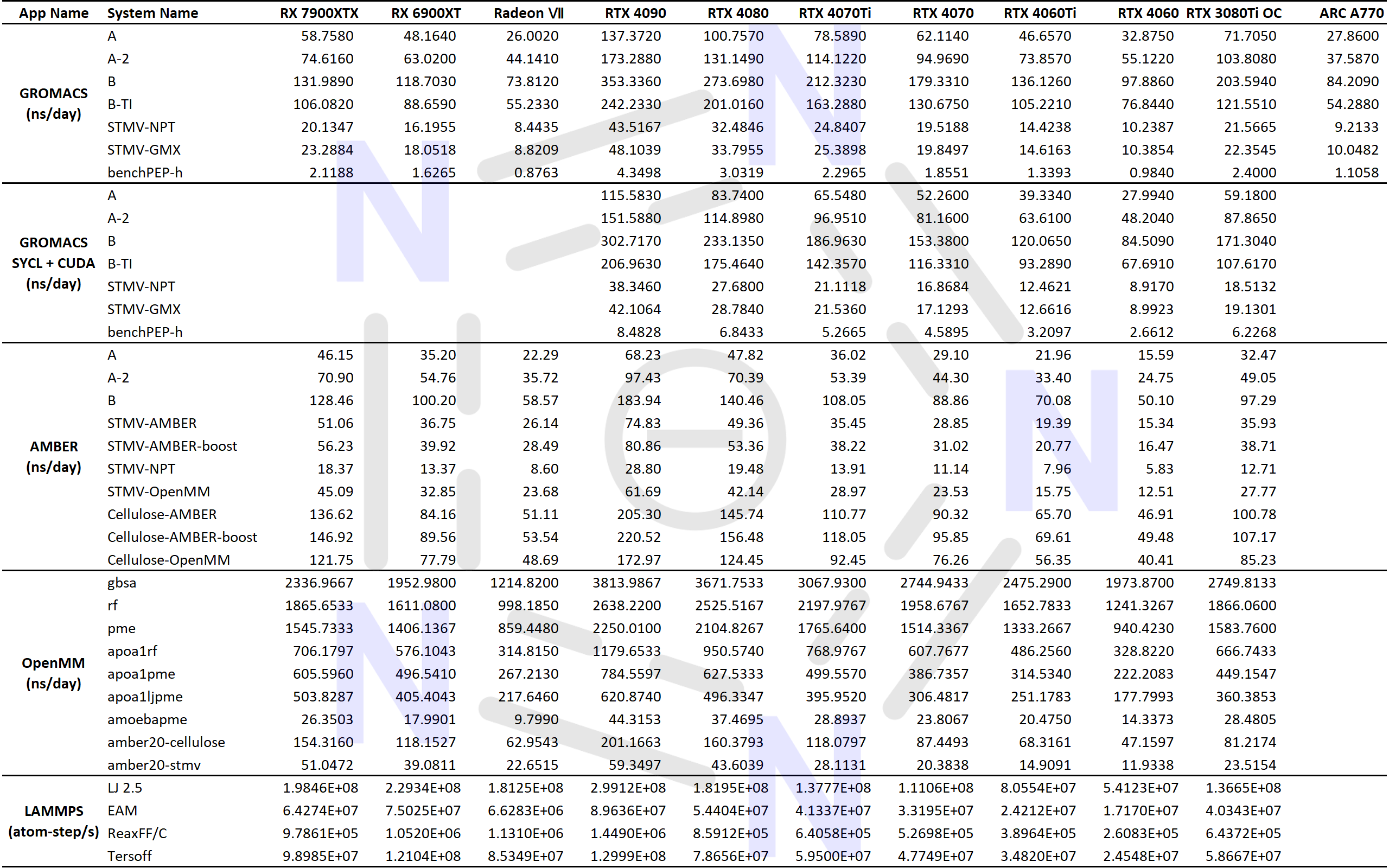
2.3 Summary table
In general, compared to NVIDIA GPUs, AMD GPUs have good performance for larger systems, but poor performance for smaller systems.
3 Supplemental instruction
The full support for SYCL is the most significant enhancement in GROMACS 2023. However, it is disheartening to note that the majority of users have not yet shown a substantial response to this upgrade. As a general guideline, GROMACS 2023 is expected to undergo a mid-to-late patch update by the end of this year or early next year. This update will enable the utilization of AMD and Intel GPUs with GROMACS 2023 for production simulations. Notably, this update aligns perfectly with the official support for RDNA 3 GPUs in the AMD ROCm software stack.
This article only showcases a fraction, less than 5%, of the data collected during this test, resulting in a somewhat generalized discussion. In reality, a significant number of controlled experiments were conducted, encompassing various factors such as different software versions, compiler versions, driver versions, floating-point precision, FFT backends, and more. Due to limitations in space and data processing, these detailed experiments were not been posted. If you guys have any specific inquiries regarding these detailed comparisons, please feel free to ask, and I will gladly provide the corresponding data, where applicable.
Similarly named systems in different applications within this article do not necessarily have the same parameters. Therefore, they cannot be used to accurately compare the performance between different applications. In the October 2022 article, I conducted a comparison of these performances and concluded that GROMACS exhibits significantly higher performance than other applications when appropriate hardware configurations and parallel parameters are set for GROMACS MDRUN. OpenMM was also included in this test; however, the actual data that could be used for a fair comparison was not presented in the article itself, although it exists. Instead, a brief conclusion is provided here: OpenMM 8.0.0 demonstrates greater performance for smaller systems, with a maximum performance of approximately 60% observed on the DHFR system, while Amber22 exhibits greater performance for larger systems, with improvements of up to around 10% seen on the STMV system. This conclusion is based on simulations conducted with the same parameters, with key considerations given to force fields, cutoffs, step sizes, thermostats, and barostats.
Regarding the hardware diversity, there is already a wealth of benchmarks available for consumer GPUs from AMD, NVIDIA, and Intel. Additionally, benchmarks exist for NVIDIA's "RTX Pro" GPUs and data center GPUs, including scattered tests found on on the Internet, official data provided by NVIDIA, and my own tests conducted a few months ago on the H100 PCIe, A100 PCIe, and V100 PCIe GPUs. However, there is a lack of public benchmarks for the AMD Instinct MI series and Intel Data Center GPU MAX series. Therefore, welcome any netizen to contribute in these areas.
文章评论