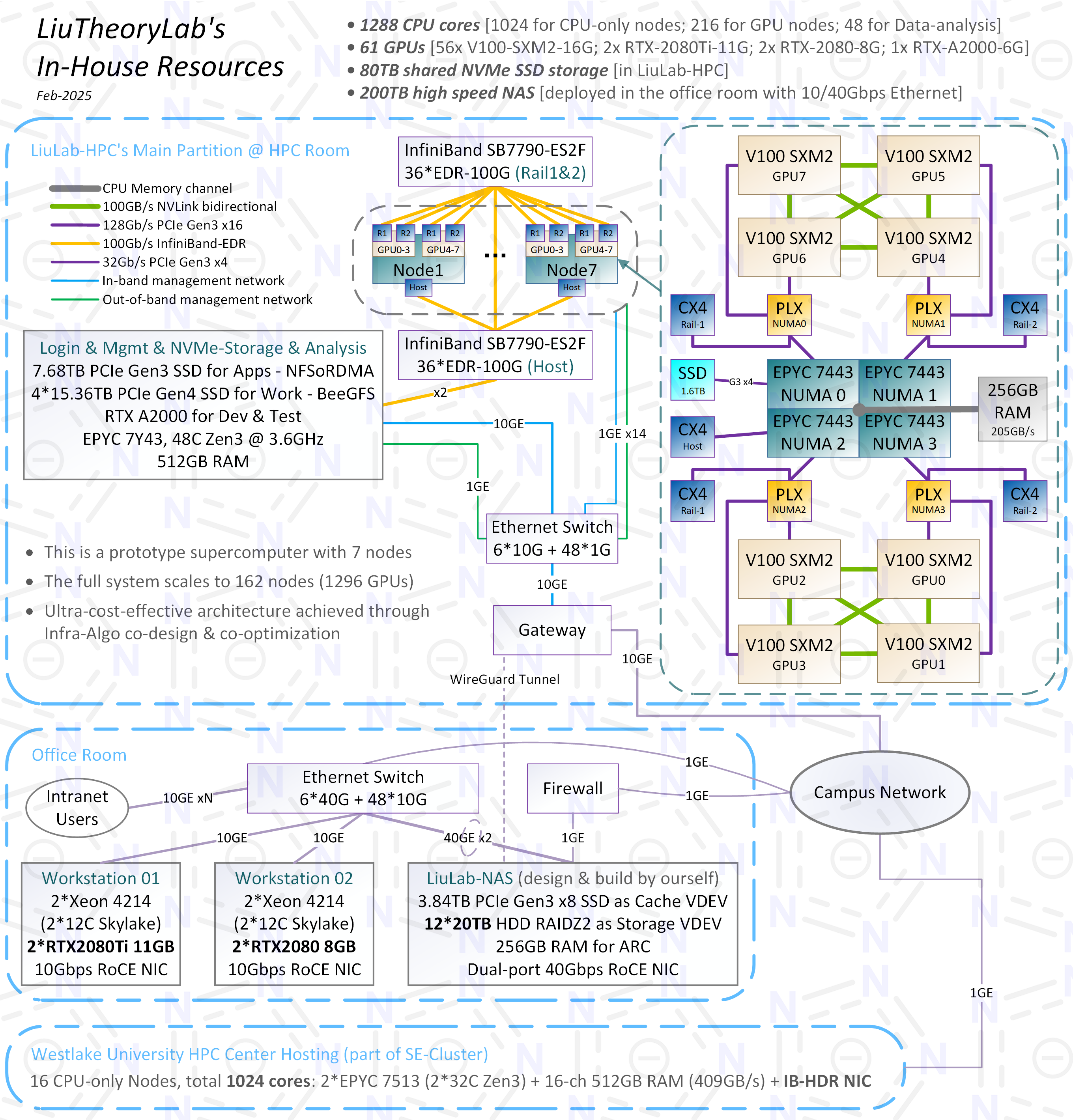
近两年以纯玩乐心态捣鼓了不少大大小小的HPC项目,亲自设计和搭建的HPC也有许多套,在此挑选近半年内由我全栈完成的3套小型HPC来写点杂谈,顺便对HPC/AI Infra行业现状发表一些意识流评论。 P1-4 我自己所在实验室的GPU集群,共7个计算节点(单节点配置参考去年夏天的贴子:手搓高性价比GPU集群),平均造价~¥3.8万。这是V100 UltraPOD 1296超级计算机的原型机,在科学计算和AI-for-Science应用中相较于DGX SuperPOD H100 […]
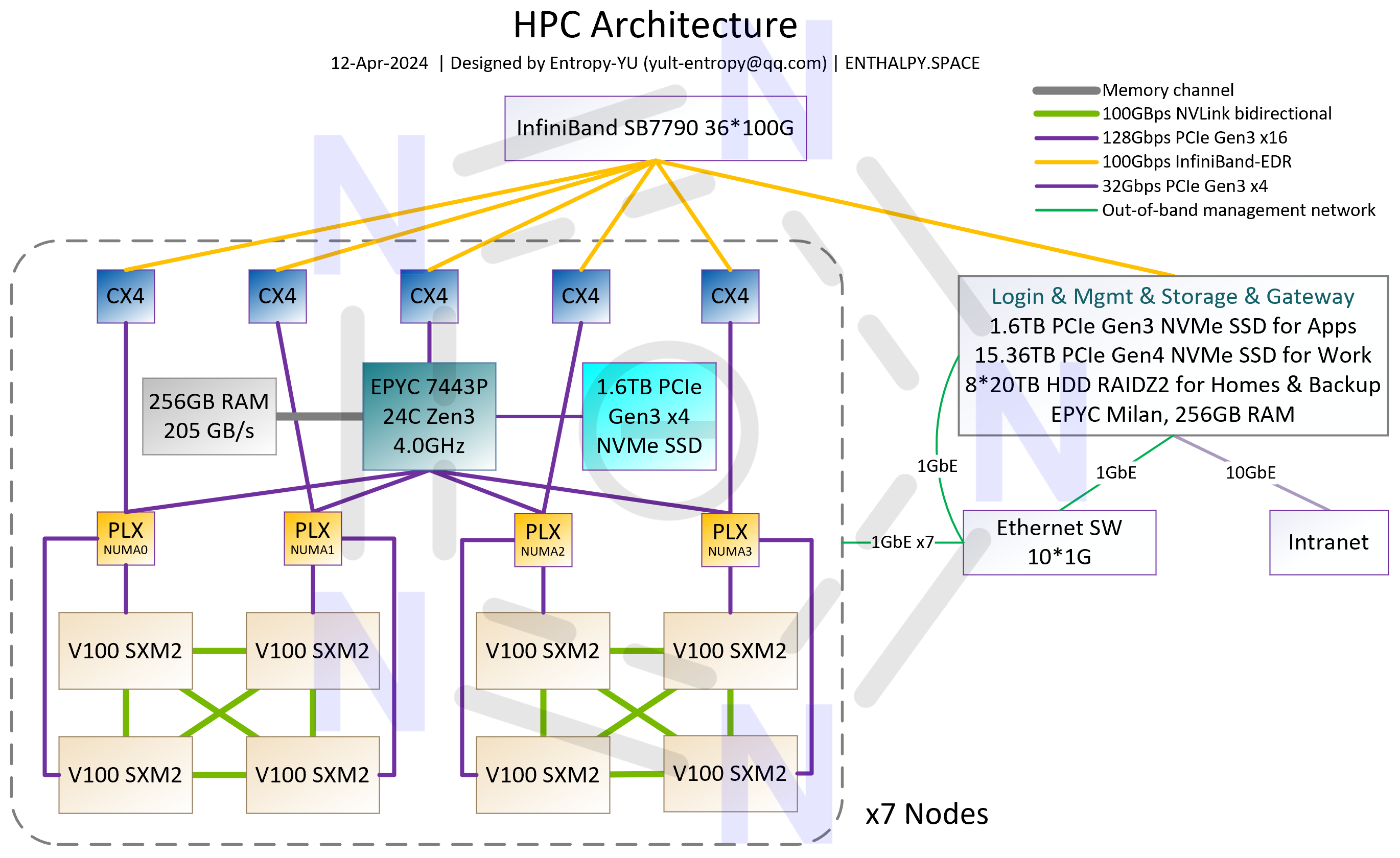
基于自己开发的服务器搭建的这套GPU集群已经在自己课题组里上线运行了一段时间(硬件如p4~9所示),跨节点并行计算性能完全符合预期,同时很稳定,至今从未出现过“掉卡”问题,比一些基于“大厂准系统”的8卡4090机器稳定多了。 目前只上了3个计算节点,24块V100 SXM2 16GB,还不是“完全体”,主要原因是机房capacity不足(白嫖机房还要啥自行车),等几个月后学校的新机房建成,也许有机会进一步扩展。 “完全体”有3种规模,架构分别如p1~3所示。其中p2的144- […]
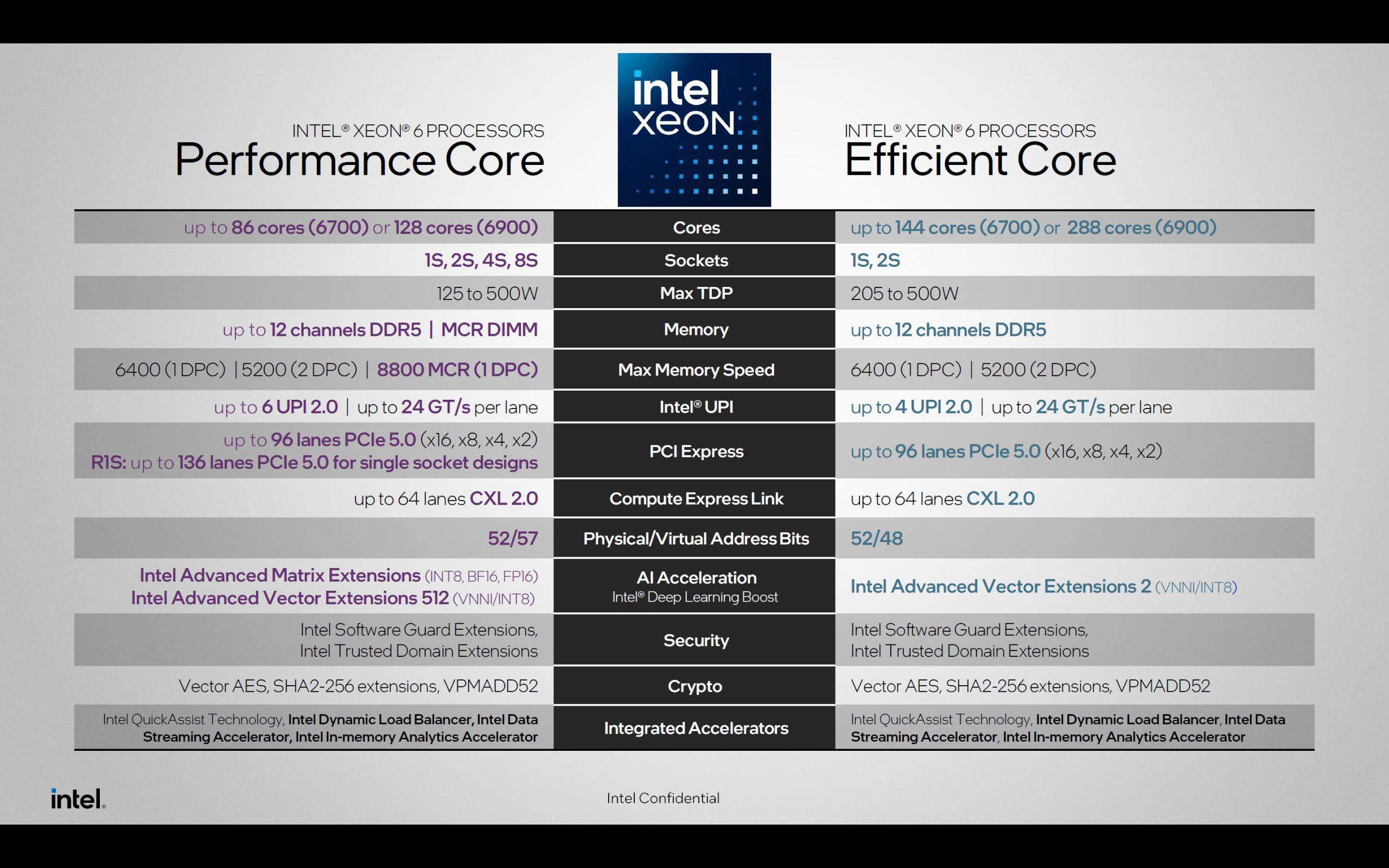
Computex 2024上intel公布了Xeon 6的一系列SKU,分LGA-4710和LGA-7529两种Socket,对应6700系列和6900系列,命名有很大变化,不过命名在技术上并不重要,重要的是Xeon 6900P分支(Granite Rapids-AP, GNR-AP)的Top SKU有希望追上AMD EPYC Turin Classic。 Xeon GNR-AP的内核微架构是Redwood Cove,与Meteor Lake P-core的Redwood C […]
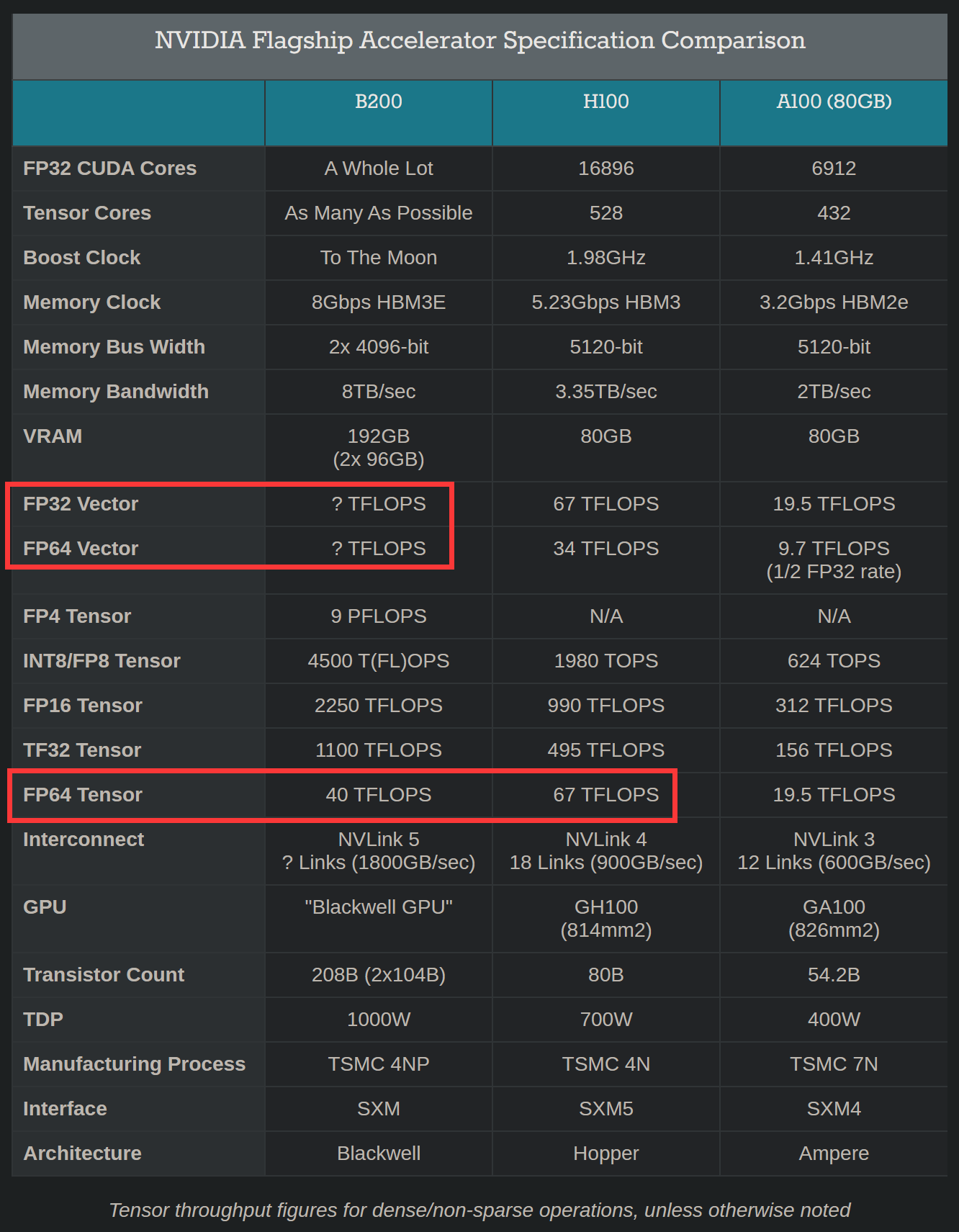
作为科学计算研究人员,站在HPC/科学计算的角度评论一下昨天发布的Blackwell GPU。 1. 完全没提到Vector算力,包括FP32 Vector和FP64 Vector。而这两者是HPC最主要使用的算力,由所谓的CUDA Core提供。FP64 Tensor算力相较于上代H100也倒退了,64TFLOPS>40TFLOPS,另外,作为对比,AMD Instinct MI300X的FP64 Matrix是163TFLOPS。NVIDIA放弃HPC是意料之中的 […]

0 写在前面 9月初笔者给朋友课题组设计了一套小集群,为了省钱,存储(NAS)部分是自行采购散件DIY的,组网也使用了二手硬件。NAS和交换机从下单散件到组装、调试完毕花了10天,原计划等到集群部署完成后综合起来写一篇帖子分享出来,但期间出现了一些问题,计算节点迟迟没有到货,故先把NAS部分单独发出来。 1 简介 采购这些散件已过去一个多月,行情有很大变化,因此价格仅供参考。 如果追求极致省钱,网卡也可以选用同为CX3 Pro芯片的拆机HP544+FLR。 18TB HDD没 […]

本月初,应某超算平台邀请,为其GPU节点运行GMX的性能做了一点Benchmark,在这里跟uu萌分享捏(其实是邀请的是我老师,她把这活转给我干乐) 对于GMX用户嘛,总结起来就一句话:别去用没有NVLink且CPU很弱的GPU集群(什么废话x 附上测试的原始数据: 本文同步发表于计算化学公社论坛