——关于“跑经典MD的计算机到底选什么配置”的终极讨论
[本文首发于计算化学公社 | 文 熵增焓减 | yult-entropy@qq.com | 2023-03]
0 写在前面
为防止太早过时,本文不会给出具体的配置单,然而本文所写的方案框架也只是基于近期硬件行情得出的,半年到一年后本文所写的方案依然可能过时,故此类内容会不定期更新,欢迎持续关注。
1 GMX
GMX机子的配置方案是最复杂、最值得仔细考虑的,GMX中的GPU加速在去年10月的文章中已经有所介绍,且GMX手册中写得更详细,这次就不赘述了。需要注意,下面会出现同样的CPU搭配不同数量的GPU,或同样数量的GPU搭配不同CPU的情况,归根结底是每块GPU分到的CPU资源不同,以及部署密度不同,这需要诸位明确自己的需求和预算,并参考本文测试结果来做选择。不过这些方案使用的GPU都是4090,且分给每块4090的CPU资源不会少得太极端,故不同方案之间单个模拟性能的差距不会超过20%,后文雷达图中单个模拟性能的差距看上去很大是为了方便区分。
1.1 MD计算节点配置
1.1.1 纯消费级平台
13900KF + 1 / 2RTX4090(DIY参考单价¥22000/36500)、7950X + 1 / 2RTX4090(DIY参考单价¥21000/35500)都是较优的方案。
13900KF + RTX4090和7950X + RTX4090在常规用法下具有极致的单个模拟性能,性价比很高,且自己组装很简单,如果必须采购品牌整机,也非常容易采购到性价比较高者(一些品牌电竞整机)。
13900KF + 2*RTX4090以及7950X + 2*RTX4090是向极致的整体性价比妥协的产物,稍微牺牲了一点单个模拟性能,且须DIY,把PCIe x16拆分为2个PCIe x8(转接套件在TB上有现货,前提是主板支持此拆分模式),还要自己想办法稳妥地安放两块4090(现有的支持显卡竖装的机箱只能支持1块显卡竖装,另一块怎么放要自己想办法)。或许可以选择板载2个CPU直出且支持配置成x8 / x8模式的PCIe x16 slot的主板(例如微星Z690 Carbon、微星X670E Carbon),再选择水冷或涡轮(离心风扇)散热的4090,这样直接装就行,不需要多折腾,也可能更美观,但会导致整机多花5000~6000元,偏离了极致性价比的初衷,适合懒癌患者。
另外,7950X + 2*RTX4090和13900KF + 2*RTX4090相比有个隐藏的优点,即前者2块4090分到的CPU资源基本相同,故同时进行的2个参数相同的模拟的速度也基本相同,可以同步得到结果,更便于调度和使用;而后者一块4090用8个P-Core,另一块4090用16个E-Core,根据测试,GPU-resident模式下16个E-Core比8个P-Core慢5~10%。此外,有些人预算很有限,需要让同一台机器做各种类型的计算,涉及到一些纯CPU并行的计算,此时线程间负载更均衡、不必担心调度问题的7950X就有明显优势。
1.1.2 专业工作站平台
2495X + 3 / 4*RTX4090、3475X + 4 / 5 / 6*RTX4090、3495X + 5 / 6*RTX4090都是较优的方案,需注意CPU必须超频使用,参考上一篇文章。
对于2495X,主板可使用华硕Pro WS W790-ACE,但ACE无BMC/IPMI功能,若对此功能有刚需,需要另购华硕IPMI扩展卡,而若将此扩展卡插在板载PCIe slot上,则第4块4090只能获得PCIe4.0 x8速率,故建议自行从板载SlimSAS接口转出1个PCIe slot用于安装IPMI扩展卡(转接套件在TB上有现货)。也可以使用华硕Pro WS W790E-SAGE SE,主要好处是不需要另外转接IPMI扩展卡,且可以直接在主板上插4块双宽4090,不是必须用定制机箱+PCIe延长线乃至分体水冷方案。
对于3475X和3495X,主板应使用华硕Pro WS W790E-SAGE SE。若预算极高,达到百万级别,建议使用3475X + 6*RTX4090或3495X + 6*RTX4090作为MD计算节点搭建集群,主板上剩余的1个CPU直出PCIe x8 slot用于安装56G IB卡;若要用100G IB卡,应当选择支持PCIe 4.0者,否则插在PCIe x8 slot上无法跑满100G,不过目前支持PCIe 4.0的100G IB卡还比较贵。
最后,根据笔者的了解,这些专业工作站平台的方案都有对应的品牌整机产品正在开发(包括塔式和机架式),且性价比不会比自行组装差太多,适合必须采购整机者,也适合需要大规模采购并部署集群者,但如果是某些暴利服务器/工作站品牌,性价比直接归零(个别品牌方利润率甚至超过60%),建议抵制此类产品。不过,需要注意的是,由于一些特殊原因,对于3475X + 5 / 6*RTX4090、3495X + 5 / 6*RTX4090这4个配置,在品牌整机中只能使用分体水冷,因此售价相对较高,但其中6*4090配置的部署密度达到了极致,故对于需要大规模采购和部署者仍然非常推荐,当然,这种情况下5*4090就完全不推荐了,因为这仅仅是给预算“刚好”只够买这套单机且有条件DIY者准备的方案。
1.1.3 各配置的直观对比
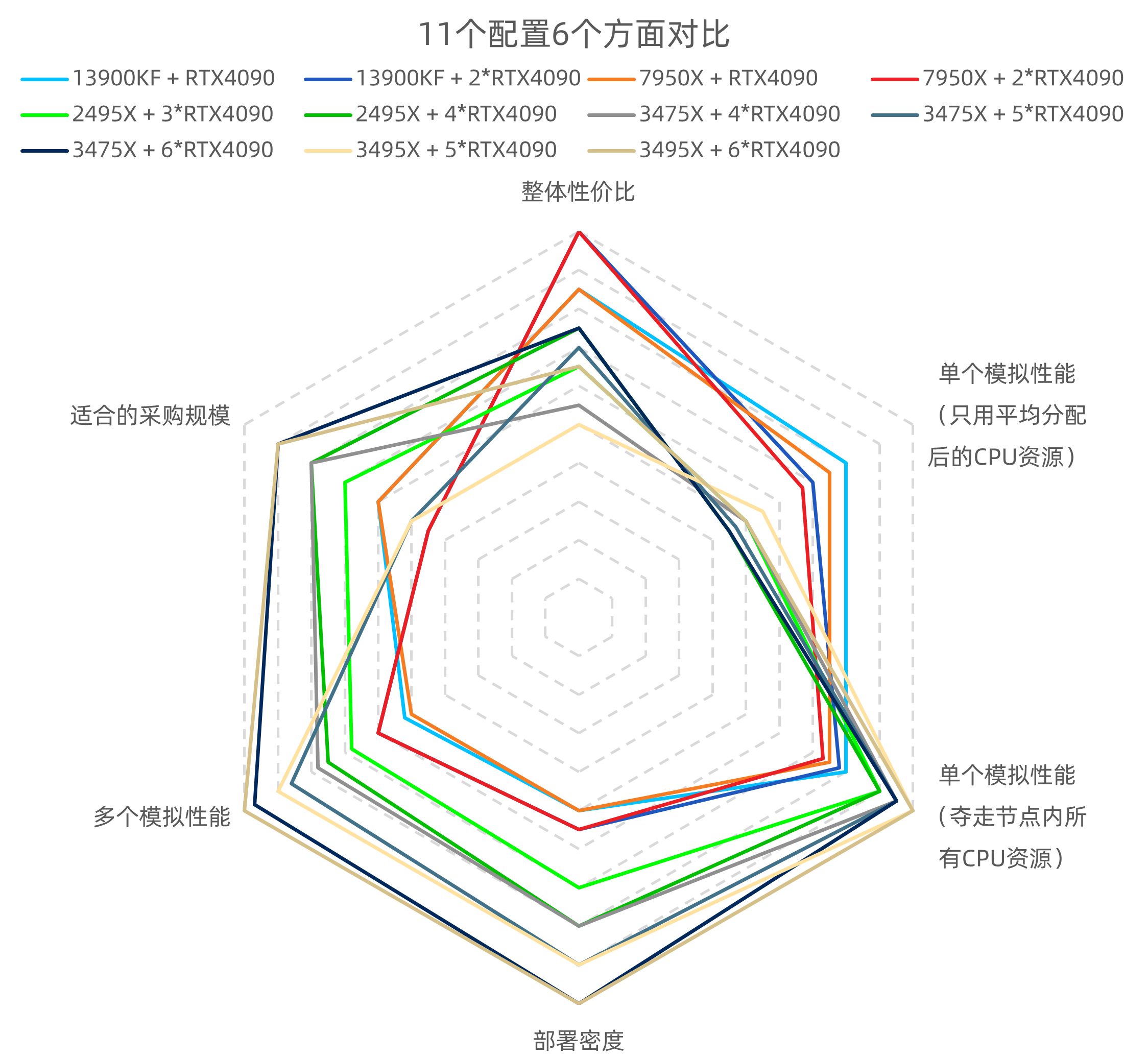
图 1 (此图使用广色域屏幕并尽可能放大后阅读更佳,对于某些平台,应下载原图后阅读)
此雷达图以5分为基准,若某个配置的某个方面低于5分则可认为这是一个明显的缺点。不难发现,有些配置看起来似乎平平无奇、不上不下,甚至有明显缺点,但仍然作为推荐的配置,这是因为许多时候采购经费是固定的,要尽可能多花又不能花超,所以需要在性价比合理的前提下给出更多整机单价不同的配置方案。值得一提的是,每个配置的具体方案都有许多,这些具体方案的某些指标可能会与雷达图有区别。例如13900KF + 2*RTX4090和7950X + 2*RTX4090,若用前文所述“美观”的方案,则“整体性价比”、“部署密度”和“适合的采购规模”这3项指标与雷达图中有显著区别(下调1.5格、上调0.5格、上调1.5格)。又例如3475X + 6*RTX4090和3495X + 6*RTX4090,若用品牌整机方案,则“整体性价比”和“适合的采购规模”这2项指标与雷达图中有显著区别(下调2格、上调1格)。
1.2 整体方案(按预算讨论)
1.2.1 2万及以下
这个预算太少,上文最便宜的配置都需要2.1万元。1.9~2万可以降一降CPU和主板,例如7700X配便宜的B650(此时加-bonded gpu大概率更快),相应地,电源也可降到850W;预算再低一些只能捏着鼻子买4080乃至4070Ti。
1.2.2 2~10万
这是目前比较常见的课题组采购预算。1~4台13900KF / 7950X + RTX4090,或1~2台13900KF / 7950X + 2*RTX4090,可以每台机器配置大容量HDD,也可另配1台NAS,视具体情况而定(若机器大于等于3台或之后有再采购的计划,建议这次先配好NAS)。
1.2.3 10~20万
这也是目前比较常见的课题组采购预算,处于比较“尴尬”的区间,可以分2类方案。
第1类方案:3~6台13900KF + RTX4090或2~4台13900KF + 2*RTX4090作为MD计算节点;1台纯CPU节点(推荐7950X)专用于分析MD轨迹;1台可用容量50TB以上、网络速率10G及以上的NAS用作存储节点,若MD计算节点大于3台,建议在NAS上建虚拟机用作ssh跳板机;1套2.5G及以上局域网。若之后有再采购的计划,则这次所配NAS以及局域网的性能应当满足之后的计划,建议这次一步到位采购8盘位及以上的NAS(盘位不插满),局域网提升到10G,并确保NAS获得20G及以上网络(例如给NAS用双口10GbE网卡并配置端口聚合,相应采购支持端口聚合的10G交换机;或直接给NAS用40GbE网卡,相应采购10GbE+40GbE交换机),而NAS扩容可以等下一次采购。工位是否通过集群的局域网访问单位局域网、互联网,需看你单位具体规定,若不允许,可给工位PC配置2块网卡,1块接入校园网,另1块接入集群,应当通过尽可能高的速率接入集群。
第2类方案:2台2495X + 3 / 4*RTX4090,或1台3475X + 4 / 5 / 6*RTX4090,或1台3495X + 5 / 6*RTX4090;1套2.5G及以上局域网。整体性价比不如第1类方案,但密度更高。此方案不推荐另配1台NAS和1台数据分析节点,给每台机子装大容量HDD即可。若之后有再采购的计划,NAS和数据分析节点可以等下次采购,而这次采购的网络设备应提升到10G,并确保可使之后添加的NAS获得20G及以上网络,例如用支持端口聚合的10GbE交换机或直接用10GbE+40GbE交换机。
1.2.4 20~80万
在这个预算区间内,仍推荐组建无IB网络的mini集群。
若干台2495X + 3 / 4*RTX4090或3475X + 4 / 6*RTX4090或3495X + 6*RTX4090作为MD计算节点;1台纯CPU节点(推荐7950X)专用于分析MD轨迹;1台可用容量100TB以上、网络速率40G及以上的NAS用作存储节点,若MD计算节点大于3台,建议在NAS上建虚拟机用作ssh跳板机,同时以此分担部分并行度高的MD轨迹分析工作;1套10G及以上局域网。
1.2.5 80万以上
推荐组建跨节点并行集群,以便进行REMD(也称并行回火,Parallel Tempering)、Metadynamics等同时启动的模拟较多且涉及到各模拟间数据交换的MD任务。此时不推荐塔式机。
6台以上3475X + 4 / 6*RTX4090或3495X + 6*RTX4090作为MD计算节点,MD计算节点之间通过56G或100G IB网络连接;1台纯CPU节点(目前推荐5975WX~5995WX或)专用于分析MD轨迹;1台可用容量200TB以上、网卡总速率40G及以上的NAS用作存储+登录节点,1套10G及以上局域网。
2 AMBER、NAMD3、SPONGE和Desmond等
这些都是“纯GPU”方案的MD软件,不需要很多CPU核心,最极端的情况下1块GPU配1个CPU核心就足够。且在不涉及多GPU并行的情况下,对PCIe带宽需求也极低,故可以使用PCIe x16拆分为2个x8甚至4个x4的方案,下文会具体介绍。
2.1 MD计算节点配置
2.1.1 DIY
7600X + 1 ~ 5*RTX4090(DIY参考单价¥19000 ~ 70000)是较优的方案,若预算卡得比较准,搭配2或3块RTX 4090的方案也可以选择。
与1.1.1节的情况类似,搭配2块及以上RTX4090,需选择支持PCIe拆分的主板。另外,对于搭配3 ~ 5块4090的方案,TB上有现成的定制机箱可用,这种机箱的思路是把4块4090固定在主板背面,注意选择合适的PCIe拆分卡,第5块4090可安装在另一个规格大于等于PCIe4.0 x4的PCIe slot上(物理形态应当是x16尺寸或更短但尾部开口的),注意可能存在的PCIe slot共享带宽的问题。
2.1.2 品牌整机
务必使用单核性能强的CPU,不要被忽悠选服务器CPU。13600K / 7600X + 1 / 2*RTX4090、2455X + 4*RTX4090、3435X + 6*RTX4090都是较优的方案,若预算卡得比较准,2455X搭配3块RTX 4090的方案也可以选择。需注意2455X和3435X应超频到5GHz左右使用。如果实在找不到13600K / 7600X搭配RTX4090的品牌整机,CPU可适当提升,但要尽可能少浪费。
2.2 整体方案(按预算讨论)
2.2.1 2万以下
1台7600X + RTX4090,如果还要低,进一步降配置的思路是优先降CPU多核性能、主板规格、RAM大小,接下去删除SSD保留HDD,最后再考虑降GPU和电源。
2.2.2 2万~10万
1台7600X + 1 ~ 5*RTX4090(DIY)或1~2台13600K + 1 / 2*RTX4090(品牌整机)或1台2455X + 4*RTX4090(品牌整机);1套2.5G及以上局域网;不需要NAS,为每台机器配置大容量HDD即可。
2.2.3 10万~20万
第1类方案(DIY):1~2台7600X + 5*RTX4090,存储和网络参考2.2.2节。
第2类方案(品牌整机):1台3435X + 6*RTX4090或2台2455X + 4*RTX4090,存储方案参考2.2.2节。
2.2.4 20万~80万
若干台3435X + 6*RTX4090或2455X + 4*RTX4090,存储和网络参考1.2.4节。
2.2.5 80万以上
整体与1.2.5节类似,MD计算节点改为若干台3435X + 6*RTX4090。
3 LAMMPS
LAMMPS的主要优势是支持的力场/势函数非常丰富,其中有许多GMX不支持的、精度较高的力场/势函数,例如反应力场ReaxFF、多体势EAM等。一般来说,特意使用LAMMPS的主要理由就是此。若要应用这些力场,则很有必要使用双精度版LAMMPS进行计算,而此时双精度性能羸弱的NVIDIA GeForce GPU和一些二手、前代的数据中心/计算专用GPU(例如Tesla P100、Telsa V100 16G)相比,性价比就不高了。当然,若只能选择全新货,那么4090与H100和A100系列相比,在跑LAMMPS方面性价比依旧极高,具体可看计算化学公社上本文的回帖。
假如你确定自己完全不使用双精度版LAMMPS,那么4090的性价比依旧是“无敌”的,此时还需要注意一点,当前Kokkos加速包不支持单精度/混合精度(开发者说今年晚些时候可能会增加此支持,但鉴于2020年他们曾说过相同的话,后来以“低优先级任务”为由一再推迟,故这次的“承诺”需谨慎看待),要使用单精度/混合精度,就需要编译传统的“GPU”加速包,此加速包不是“纯GPU”方案的,类似于GMX,因此这种情况下的计算机配置方案应当参考本文第1节,本节不再另行列出。
假如对单个模拟的速度要求比较高,就要考虑使用多块GPU运行1个模拟,此时应该使用PCIe lane充足的单路CPU平台,让每块GPU之间都具有满速PCIe P2P连接(GeForce GPU无PCIe P2P,故不能用于此方案)。最推荐的平台是AMD TR Pro,核数不需要很多,选择低端SKU即可,例如5955WX,重点在于需要选择具有足够多的PCIe x16 slot的主板,例如超微M12SWA-TF。
最后再提示一下,LAMMPS中有些pair_style不支持GPU加速,若你有可能用到这些pair_style,则应当另外配一台专注于CPU密集型任务的工作站/服务器;当然,在预算很低的情况下,7950X搭配合适的GPU,把纯CPU计算和GPU加速合并在1台机器上,也是非常不错的方案。
3.1 DIY
7600X / 7950X + 1 ~ 5*Tesla P100 / Tesla V100 16G / TITAN V / RTX4090,或5955WX + 6*Tesla P100 / Tesla V100 16G / TITAN V,安装方法与2.1.1节类似,即选择为安装大量GPU设计的特殊机箱。
核心思想是尽可能买1000多元的二手P100以及3000多元的二手V100 16G或TITAN V。
3.2 品牌整机
如今品牌整机已基本无法选配P100、V100、TITAN V这些老GPU,因此本文只推荐RTX4090,虽然RTX4090双精度性能羸弱,但用来跑LAMMPS的性价比远高于H100、A100全系列。配置照搬本文第2节方案即可。
4 关于GPU选择的特别说明
当前,做经典MD模拟完全不推荐购买A100、H100系列;即使对于LAMMPS,也完全不推荐。若预算达到百万以上,且对单个模拟性能有极端需求,那么可以用包含8块SXM版A100/H100的NVIDIA HGX。实际上,追求暴力MD会让成本上升到令人难以接受的程度,还无法与真正财大气粗的团队(例如拥有ANTON系列MD专用超算的DESRES)竞争。而如今增强采样(Enhanced Sampling)方法已经非常丰富,这类方法的普遍特点就是可以并行运行许多模拟,每个模拟不需要很长的时间尺度即可实现很好的采样效果,效率比暴力MD高得多;各模拟之间的数据交换量较少或没有,所以完全不需要计算专用GPU上的高速互联功能(如NVLink),用消费级GPU性价比极高。例如200万预算,可以组建包含约80块4090的高性能集群,也可购买1台包含8块H100 SXM5的HGX H100,而在前者上跑主流的增强采样MD,获得有效结果的耗时比在后者上跑暴力MD短至少1个数量级。总之,即使你有上百万预算,也应当优先考虑用数十块4090组建集群,而非盲目购买A100、H100。此外,从Ada世代开始,RTX6000Ada之类“专业绘图”GPU上的NVLink也被彻底取消了,而这类GPU用的是与同世代消费级GPU架构完全相同的核心,FP64性能也极弱,因此在LAMMPS以及其他需要FP64加速的AIMD程序上也没什么用,综上,现在这类GPU在整个MD领域已一无是处,完全不推荐购买。
5 如何采购?
经常看到有人说“反正不是我的钱,买的东西性价比低也不心疼,怎么舒服怎么花”之类的的言论,这显然非正人君子之态度,难道公费就可以随意挥霍吗?道理不言自明。
还有人说“学校里政府采购,自己决定不了供应商”,这很值得讨论。《中华人民共和国政府采购法》第五条:任何单位和个人不得采用任何方式,阻挠和限制供应商自由进入本地区和本行业的政府采购市场。第八十三条:任何单位或者个人阻挠和限制供应商进入本地区或者本行业政府采购市场的,责令限期改正;拒不改正的,由该单位、个人的上级行政主管部门或者有关机关给予单位责任人或者个人处分。若真有限制供应商的情况,这本身就是不合法的。若你不敢利用法律反驳,也完全可以事先与指定的供应商商量具体配置方案,即使这些供应商自己不能直接提供你想要的配置,也可以把项目转给其他的商家(事实上多数情况下都是这么干的,因为这些“指定供应商”往往是皮包公司),虽然这样最终到手性价比可能会比本文雷达图中所标的低一些,但不会低太多,至少不会比某些暴利、严重溢价的品牌整机低,且可以确保拿到的是最合适的配置,而不是“单核性能很差的CPU配多块4090”、“10万预算配1块A100/A800/RTX6000Ada跑GMX/AMBER”、“8个内存通道只用了2个”等不合理配置(对于内存通道浪费的情况,一般借口是“自己回去加内存”,而事实是品牌整机的内存兼容性低得令人发指,笔者所在实验室用的某品牌双路工作站,曾无数次出现无法开机的问题,售后拖了4个月上门换主板后问题依旧,最终是笔者自己排查到问题出在混用同参数但不同生产日期的DIMM上)。总之,大多数人说“自己决定不了供应商”只不过是不愿意多做点沟通工作罢了,一个字概括,即“懒”。
再专门说说前文多次提到的“溢价的品牌整机”。首先,并非所有品牌整机都是严重溢价的,只要你愿意在这个行业里多打听,必然可以找到售后好、溢价少且具有intel等上游厂商认证的正规品牌整机。其次,那些严重溢价的品牌整机普遍以“售后服务”、“稳定性”和“安全性”作为溢价理由,然而,对科研用途来说这3项指标并不足以支撑某些品牌整机翻数倍的溢价幅度。先说“售后服务”。以京东自营作为对比,京东自营的售后服务是大众公认的顶级水平,只要消费者提交理由合理的售后申请就几乎必然通过,对于不便维修的商品还能提供换新、上门换新甚至退货退款(笔者作为在京东购买过上千件商品、提交过近百次售后申请的人,应该比较有发言权),有这样优质的售后服务,京东自营商品并没有有翻倍溢价,甚至在一些促销活动中价格比其他平台还低。有人说整机商售后“很专业”、“上门速度快”,然而这些品牌商大多数售后服务人员都是外包的,专业水平参差不齐,水平比较差的还不如用户自己;那些有水平的“编内人员”数量稀少,几乎不可能达到品牌商所宣传的行动速度,要这些人上门,那么等待时间就得按周甚至月来计。再说“稳定性”。“稳定性”是极难评估的指标,硬件配置稍微变化一点(尤其是DIMM),对稳定性都有极大影响,如果供应商不能给出具体到各配件型号的某款整机产品的权威的稳定性测试报告(一般只有原厂原装未改配置的整机才满足此条件),将其稳定性和普通消费级产品等同即可;此外,“稳定性”指标只对于企业应用以及保障社会稳定运行的用途比较重要,而对于“意外情况”本就如同家常便饭、经费贫瘠、人均技术水平较高的基础科研领域来说几乎不值一提,遑论以此无限溢价。最后说“安全性”。这可分为物理上的安全和信息安全两种,前者只要通过国家3C认证就有保障,最低端的消费级产品都能满足;而后者主要在于人和整个软硬件体系而不在于单一的硬件,单一硬件设计再安全也难以抵御内鬼的破坏或者千疮百孔的软硬件体系,而且在科研领域,只要不是涉密项目,也不需要在硬件上专门做信息安全保障,使用基本的软硬件并把好“人”这道关足矣,对于防止数据丢失的问题,关键是备份,而非某台机器的硬件设计。总之,万万不能被吹得天花乱坠的“售后服务”、“稳定性”和“安全性”蒙蔽了双眼!
无论如何,只要采用本文推荐的方案,积极和供应渠道以及把控采购的领导沟通,避开某些严重溢价的暴利产品,必然可以获得配置合适、性价比不错的用于跑经典MD的计算机。
至此,“2023年3月MD benchmark测试”系列文章已完结,若需要具有合适排版的PDF文件(A4版面,共14页),可在此下载:https://www.aliyundrive.com/s/yqo7Pv55cpH,提取码: h1i7
文章评论