[本文首发于计算化学公社 | 文 熵增焓减 | yult-entropy@qq.com | 2023-03]
0 写在前面
去年10月的文章中说:
“如今Ada Lovelace架构刚刚上市,并无针对性优化,预计在将来几个月,随着几款MD软件以及编译器和驱动层面对于Ada Lovelace架构的优化,RTX 4090运行MD模拟的性能还会有进一步提升。”
如今已过去5个月,是时候检验一下自己是否被打脸了。
1 测试平台
硬件:
| ID | CPU | GPU | 内存-RAM | 主板-Mother Board |
| 1 | AMD Ryzen R9 7950X | NVIDIA GeForce RTX 4090 | DDR5 5600MT/s 16GB x2 | ASUS TUF GAMING X670E-PLUS |
| 2 | intel Core i9 13900KF | ASUS PRIME Z790-P |
软件环境:Ubuntu 22.04.2 LTS Desktop; Linux version 5.19.0-35-generic x86_64; GNU 11.3; CUDA Toolkit 12.1 / 11.8; NVIDIA GPU Driver 530.30.02
2 测试程序信息及相应模型参数
模型同2022年10月测试。
GMX编译了2023(CUDA runtime V12.1)、2022.5(CUDA runtime V12.1)、2022.5(CUDA runtime V11.8)、2022.3(CUDA runtime V12.1)。LAMMPS版本为8Feb2023,使用cmake预设“basic.cmake”和“kokkos-cuda.cmake”进行编译(“kokkos-cuda.cmake”中“Kokkos_ARCH_PASCAL60”改为“Kokkos_ARCH_ADA89”),同时额外指定编译REAXFF包(-D PKG_REAXFF=on)。由于AMBER22和NAMD3从去年10月至今都未更新,故这2者使用与去年10月测试完全相同的版本。虽然AMBER22是从源码编译,理论上可以自己改cmake脚本(比如修改编译器兼容性检测语句并加入SM89相关flags),但这不是合适的做法,且经过笔者实际测试,修改cmake脚本的CUDA配置模块后,基于NVCC 12.1.66编译仍然会在编译末期出错,若还是基于NVCC 11.8.89编译,虽然编译能完成,但实际测试发现性能毫无变化,故放弃此做法。
3 RTX 4090变快了多少?
如图1,从去年10月到现在,4090在4款MD软件下均有性能提升。对GMX来说,GPU-resident模式下提升最明显,最高达到了19%,平均12%左右;在bonded CPU的情况下提升也很大,平均7%左右,但对于像A-2这样bonded计算量很大的模型则没有提升,毕竟瓶颈在于CPU;在单线程的GPU-resident模式下也有平均5%左右的提升。此外,B-TI模型下的提升普遍比较小,因为CPU需要负责与自由能相关的计算,CPU瓶颈也比较明显。对AMBER22和NAMD3来说,由于至今未更新,本次测试与去年10月测试唯一的区别就是GPU驱动版本,故提升非常小。对LAMMPS来说,Tersoff模型下提升尤其明显,达到了27.5%,而另外2个模型提升却微乎其微,不过,这次测试中ReaxFF/C模型可以成功运行,只是缺少去年10月的数据作为对照,故没有在图中展示,SI中有详细数据。虽然RTX 4090跑LAMMPS变快了,个别情况下甚至变快了27%以上,但性价比还是明显不如1000多元一块的P100和5000多元一块的V100 16G,故本文对LAMMPS的测试结果仅供参考。

图 1
4 RTX 4090变快的原因
既然已经可以确认如今RTX 4090加速经典MD的性能相较于去年10月变快了,那么其中原因值得思考。
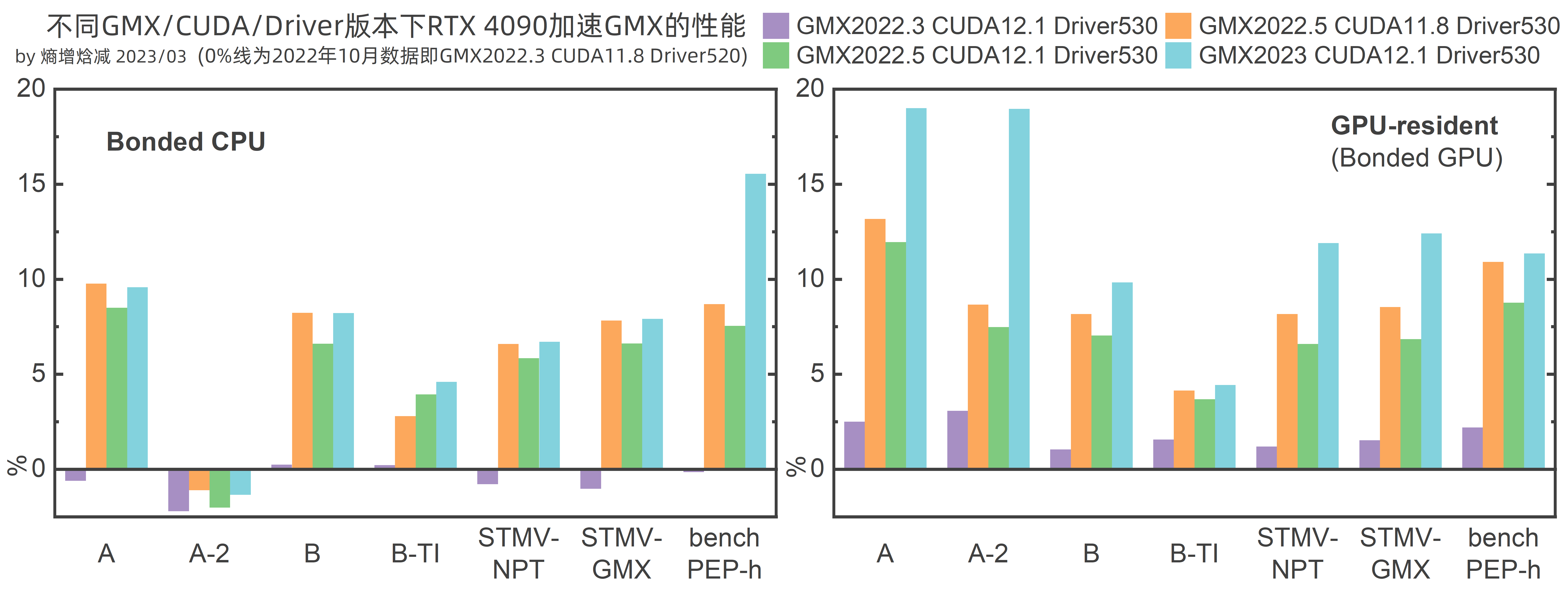
图 2
观察图2可以发现,对GMX2022.3来说,即使使用最新的CUDA和GPU驱动版本,性能提升幅度也只有3%以下,换到GMX2022.5后,即使CUDA runtime为RTX 4090刚发布时的11.8版本,性能与2022.3相比也有大幅提升,若把CUDA升级到12.1,性能却又有轻微的降低,而再把GMX升级到2023版,性能又有了一些提升,其中GPU-resident模式的性能提升更明显。查询GMX2023 Release notes可知,GMX2023确实有一些性能优化,但其中CUDA PME decomposition、CUDA Graphs和VkFFT并未在本次测试中涉及,且本次测试本来就指定了update GPU,故“Update will run on GPU by default”也不是本次测试中GMX2023性能提升的原因。
总结前面的情况,并阅读各软件的手册可以得出,让4090“变快”的原因有以下几条,其中加粗的条目是主要影响因素。
- NVIDIA GPU驱动层面优化了性能;
- 8及以后版本的CUDA适配了ADA架构,对ADA架构有特别优化(需在编译时通过指定相应的NVCC编译器flags以激活此优化);
- GMX较新版本的NVCC编译flags中增加了ADA架构(SM89)的相关条目以匹配8及以后版本的CUDA(最简单的检查方法是运行gmx -version命令,观察输出的“CUDA compiler flags”条目);
- LAMMPS较新版本的Kokkos模块的NVCC编译flags中增加了ADA架构(SM89)的相关条目以匹配8及以后版本的CUDA;
- GMX2023小幅优化了单GPU模拟的性能(一般不会被手动指定的nsttcouple和nstpcouple这2个MDP选项的默认值从10 steps增加到了100 steps;全局通信频率不再取决于nstlist)。
Anyway,现在更加可以说RTX 4090相较于RTX 3090Ti“性能翻倍”了!
SI
经简单整理的测试结果原始数据(MD_benchmark_data_Mar2023_Pub1.xlsx)。文件下载地址:https://www.aliyundrive.com/s/BwFL1TohoZU,提取码:15fd
文章评论