[本文首发于计算化学公社 | 文 熵增焓减 | yult-entropy@qq.com | 2023-03]
0 写在前面
近期intel W790平台的系列产品即将或已经上市,笔者对其中2个具有代表性的型号进行了性能测试,分别是intel Xeon w7-2495X和intel Xeon w9-3495X。
本文MD测试部分只包括GROMACS 2023,其中所用模型与此系列首篇完全一致;另增加了Gaussian 16 Rev. C.02 AVX2和ORCA 5.0.4这2个量子化学程序的测试,具体信息在后文介绍。
1 测试平台
硬件:
| ID | CPU | GPU | 内存-RAM | 主板-Mother Board |
| 1 | intel Xeon w7-2495X All-Core 5.0GHz |
NVIDIA GeForce RTX 4090 | DDR5 4800MT/s ECC-RDIMM 32GB x4 4Channels | ASUS Pro WS W790E-SAGE SE |
| 2 | intel Xeon w9-3495X All-Core 4.7GHz |
DDR5 4800MT/s ECC-RDIMM 32GB x8 8Channels |
W790平台CPU超频参数(Ai Tweaker):ASUS MultiCore Enhancement [Enabled - Remove limits],CPU Core Ratio [By Core Usage],DIGI+ VRM > CPU Load-line Calibration [Level 7],Internal CPU Power Management > Maximum CPU core Temperature [105]。3495X核心电压Auto,2495X所有核心电压offset调为+0.15V。
需要注意的是,GPU加速GMX时CPU浮点计算压力较低,功耗不高,超频调试思路与CPU密集型应用有巨大差别,后者一般不能给太高的核心电压,甚至需要降压超频,而前者应当保证核心电压足够高,用降压超频的思路反而不稳定。
CPU散热器采用ABEE SPR360,该散热器能将920W的3495X和650W的2495X的核心温度控制在100℃以内。
软件环境:Ubuntu 22.04.2 LTS Desktop; Linux version 5.19.0-35-generic x86_64; GNU 11.3; CUDA Toolkit 12.1; NVIDIA GPU Driver 530.30.02
若使用Sync All Cores方式超频3495X,在Linux下有不能解释的bug:空载功耗360W,运行低负载任务(如解压压缩包、测试核间延迟、使用较少核心运行GPU加速GMX等)性能异常地弱,大约只有正常的十分之一,但检查所用到的CPU核心频率是正常的;满载性能趋向正常,例如运行mlc(intel的内存带宽/延迟测试工具),让CPU接近满载,此时运行其他低负载的任务性能就基本恢复正常了。
2 新平台搭配RTX4090加速GROMACS的性能
对于核数如此多的CPU,考察GMX比考察其他纯GPU方案的MD程序更有意义。图1展示了相关测试结果。其中3495X只展示了前32核的数据,一方面由于需要给其他核数较少的CPU留出空间以便于阅读,另一方面由于32核后曲线接近水平,展示价值不大。若要了解详细数据(包括3495X完整数据),可下载SI阅读。需要注意的是,对于支持超线程的CPU核心,1核的含义是用完2个逻辑核心。
去年10月文章中提到,CPU核心间延迟对GPU加速GMX的性能有负面影响,因此本轮测试最先做的就是核间延迟测试。2495X和3495X的核间延迟测试结果此前已公开在BB空间和GitHub上。
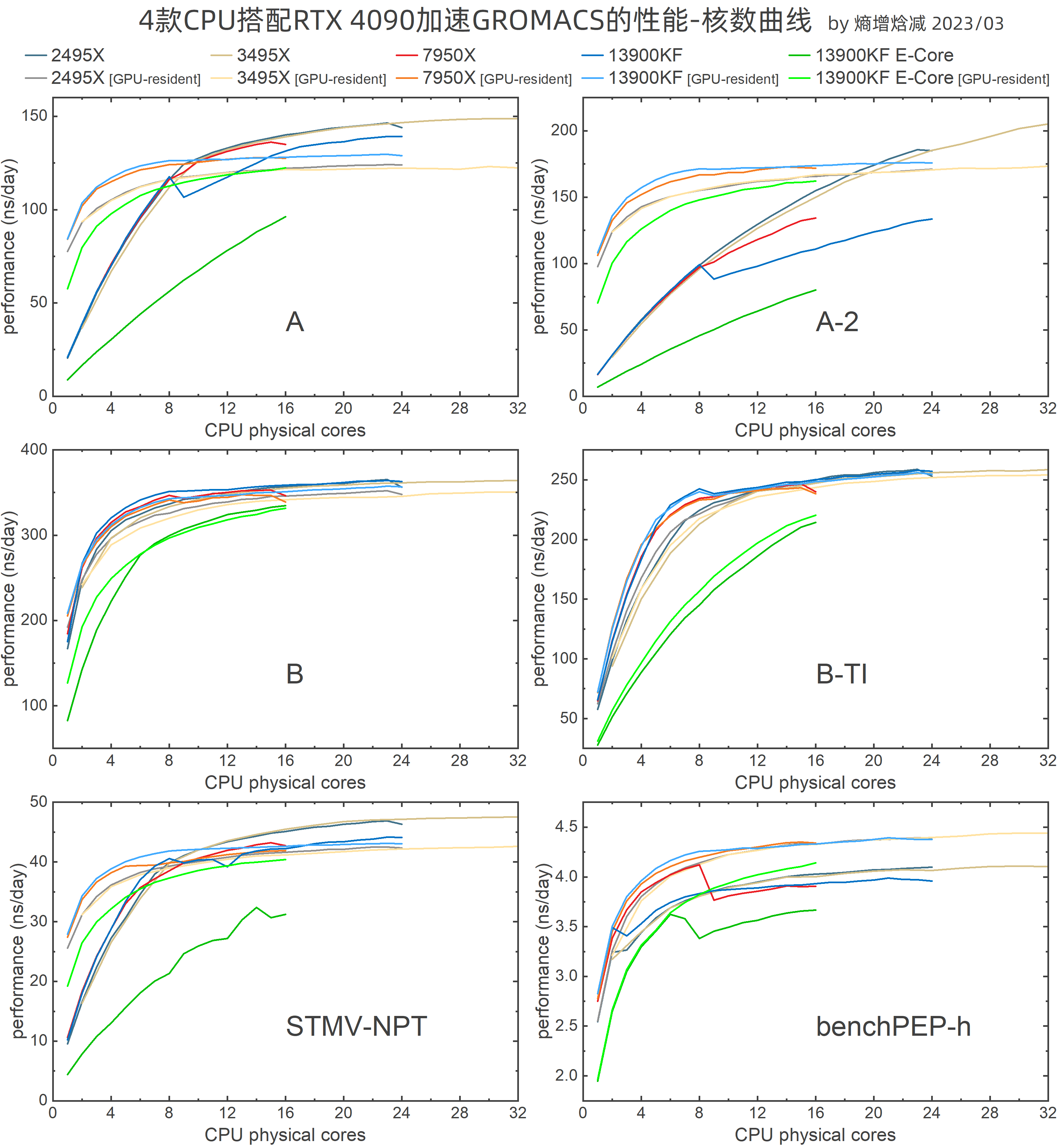
图 1 (此图使用广色域屏幕并尽可能放大后阅读更佳,对于某些平台,应加载原图后阅读)
从图中首先可以看出,同样模式中,在前8核时,2495X和3495X相较于7950X和13900KF仍有可观测的差距,而8核之后2495X和3495X全“大核”且核间延迟均匀的优势就有明显体现,逐渐接近并反超7950X和13900KF。
对于7950X和13900KF,多数情况下超过8核性能提升就不明显了;而对于2495X和3495X,多数情况下12核之后性能提升也不明显。其中GPU-resident模式(bonded GPU)到达平台区更早。显然,对于2495X和3495X这样极为昂贵、扩展性极强的CPU来说,最合适的做法是1颗CPU配合多块RTX4090,每块RTX4090分配8~12核;而对于7950X和13900KF,若要追求极致性价比,也可搭配2块RTX4090,若预算很少,还可用8核的7700X搭配1块RTX4090。关于具体的硬件搭配,在此系列文章的最终章会有详细讨论。另外,实际使用时也要注意最好给CPU留出至少1个逻辑核心用于处理系统进程和驱动开销,但如果是类似于2495X配3块4090这样可以刚好把所有CPU资源平均分配完,同时又需要用脚本批量、连续运行MD模拟+数据分析的情况,也可自行考虑是否留出1个逻辑核心(如果只让其中一个任务留出1个逻辑核心,可能需要写至少2,操作起来比较复杂),比较好的做法是每个任务都留出1个逻辑核心,这样每个任务速度基本相同,操作也不需要增加额外的复杂度。
在benchPEP-h模型的曲线中普遍出现了令人难以理解的跳跃,多次测试结果都是如此,且去年10月测试中benchPEP-h模型的曲线也有类似的情况,此现象有待详细解释。
3 特别篇:w9-3495X的Gaussian和ORCA性能
由于Gaussian和ORCA对CPU压力较大,故对3495X使用降压超频,将所有核心电压offset调为-0.1V,全核频率降为4.5GHz。
本节测试使用了武汉大学钟成老师开发的xbench3测试脚本,同时也参考了计算化学公社上已有测试所用的关键词。测试所用的体系是最经典的Gaussian Test0397,没有测试多个任务的性能,因为3495X主要优势就在于能够以更少的物理核心数达到与服务器CPU相似的理论多核性能,只测试优势项目就够了。
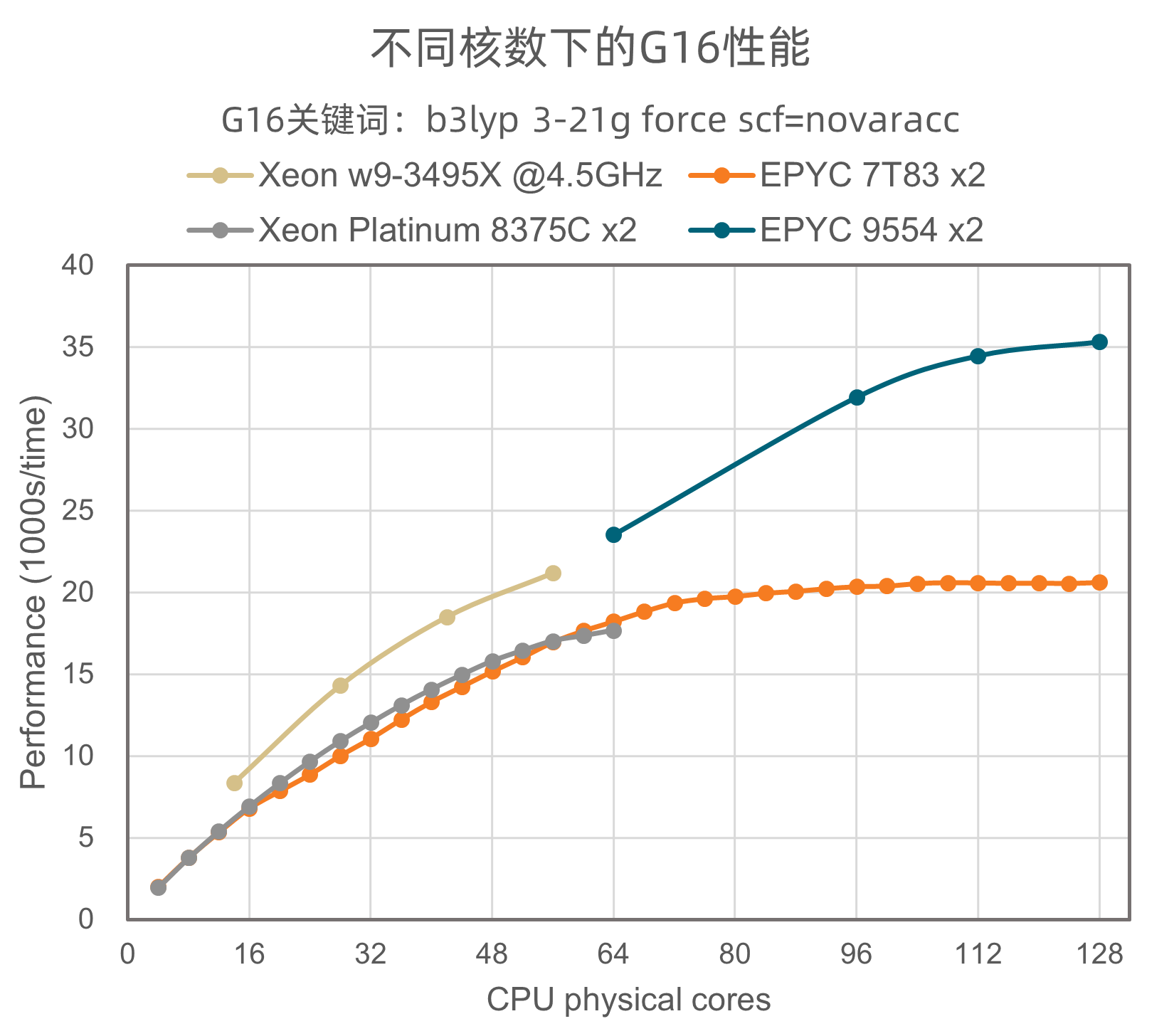
图 2
图2用双路EPYC 7T83、双路EPYC 9554和双路Xeon 8375C作为对比,在“b3lyp 3-21g force scf=novaracc”关键词下,w9-3495X大幅领先于EPYC 7T83和双路Xeon 8375C,略强于双路EPYC 7T83,但弱于单路EPYC 9554。
至于更进一步的测试,由于和其他CPU的对比都是从网络上拼凑出来的(来源:epyc 9554初测 gaussian 16,g16在8375C和7T83的表现小测评,ORCA并行效率小测试,淘宝上购买的双路EPYC 7R32 96核服务器的使用感受和杂谈),故数据不是很全,难以制图,只能以表格的形式公布。
从表2中可以发现,3495X在耗时较长的任务(即所谓的“大任务”)下可以击败单路EPYC 9554,但在“小任务”下仍不如单路EPYC 9554。在表3的ORCA测试结果中,3495X完全领先于双路EPYC 7T83和双路Xeon 8375C。此外,不论Gaussian还是ORCA,3495X在任何时候都领先于EPYC 7T83和双路Xeon 8375C,在绝大多数情况下领先于双路EPYC 7T83。
表2 Gaussian 16(单位:秒)
| ID | Keywords | Xeon w9-3495X @4.5GHz | EPYC 7T83 x1 | EPYC 7T83 x2 | EPYC 9554 x1 | EPYC 9554 x2 | EPYC 7R32 x2 | Xeon 8375C x2 |
| 1 | b3lyp 3-21g force scf=novaracc | 47.22 | 54.85 | 48.50 | 42.50 | 28.30 | 56.56 | |
| 2 | b3lyp 3-21g force scf=novaracc g09default | 24.52 | 31.52 | 24.10 | 18.60 | 31.36 | ||
| 3 | b3lyp 6-31g** force scf=novaracc | 161.45 | 151.40 | 95.70 | ||||
| 4 | b3lyp def2svp force scf=novaracc | 242.91 | 237.40 | 144.60 | ||||
| 5 | b3lyp def2svp force scf=novaracc g09default | 140.08 | 149.80 | 132.18 | 144.40 | 94.60 | 166.00 | |
| 6 | b3lyp def2tzvp force scf=novaracc | 1987.37 | 2088.50 | 1177.30 | ||||
| 7 | b3lyp def2tzvp force scf=novaracc g09default | 1192.46 | 1714.98 | 1245.68 | 1272.70 | 738.20 | 1350.00 | 1736.30 |
| 8 | B3LYP def2SVP scf(tight) g09default | 96.77 | 121.65 | |||||
| 9 | B3LYP def2TZVP scf(tight) g09default | 1004.55 | 1408.45 | 1020.40 | 1408.45 |
表3 ORCA 5.0.4(单位:秒)
| ID | Keywords | Xeon w9-3495X @4.5GHz | EPYC 7T83 x1 | EPYC 7T83 x2 | Xeon 8375C x2 |
| 1 | B3LYP def2-SVP tightscf | 116.51 | 172.41 | ||
| 2 | B3LYP def2-TZVP tightscf | 388.33 | 571.43 | 500.00 | 568.18 |
| 3 | r2SCAN-3C tightscf | 85.01 | 115.21 | 131.93 | |
| 4 | cc-pVDZ cc-pVDZ/C DLPNO-CCSD(T) NormalPNO TightSCF | 1136.29 | 1250.00 | 1350.00 |
上述情况是非常、非常令人意外的,因为EPYC 9554的理论多核性能比全核心4.5GHz的w9-3495X弱,理论上来说前者运行Gaussian和ORCA的性能不应该比后者强。目前只能找到1个明确的原因从一定程度上解释此状况,但不能完全解释。3495X在跑较小的任务时单轮SCF计算很快,而在切换到下一轮时有一个CPU负载较低的阶段,于是CPU在高负载和低负载之间快速反复切换,相应地,CPU频率也在高低之间快速反复切换,低负载时CPU频率只有2.9GHz甚至1.9GHz(即base clock),且从低频切换到高频的反应比较迟钝,频率boost机制不能很好地发挥,影响了性能,这可能由于BIOS没有优化到位(类似的问题在默认BIOS设定下测试CPU核间延迟时也存在,笔者在GitHub上和网友提到过此事)。另一个可能的原因是w9-3495X的RAM只有8通道DDR5 4800MT/s,与AMD EPYC 9004系列的12通道DDR5 4800MT/s相差极大,故w9-3495X超频至全核心4.5GHz后的高频优势被EPYC 9004系列的内存带宽优势扳回。
总之,由于w9-3495X超频后全核频率达到4.5GHz,能够以更少的物理核心数达到与双路EPYC 7T83相同的理论多核性能,减弱了高并行度下的边际效应,故w9-3495X在Gaussian和ORCA战胜了双路EPYC 7T83;但又由于各方面的、已确认或还未确认的原因,w9-3495X似乎不能超过单路EPYC 9554。需要注意的是,互联网上关于EPYC 9554的测试没有给出详细的关键词(例如是否加了“scf=novaracc”,这非常重要),结合目前令人意外的对比结果,关于w9-3495X不如单路EPYC 9554的结论有待进一步确认。
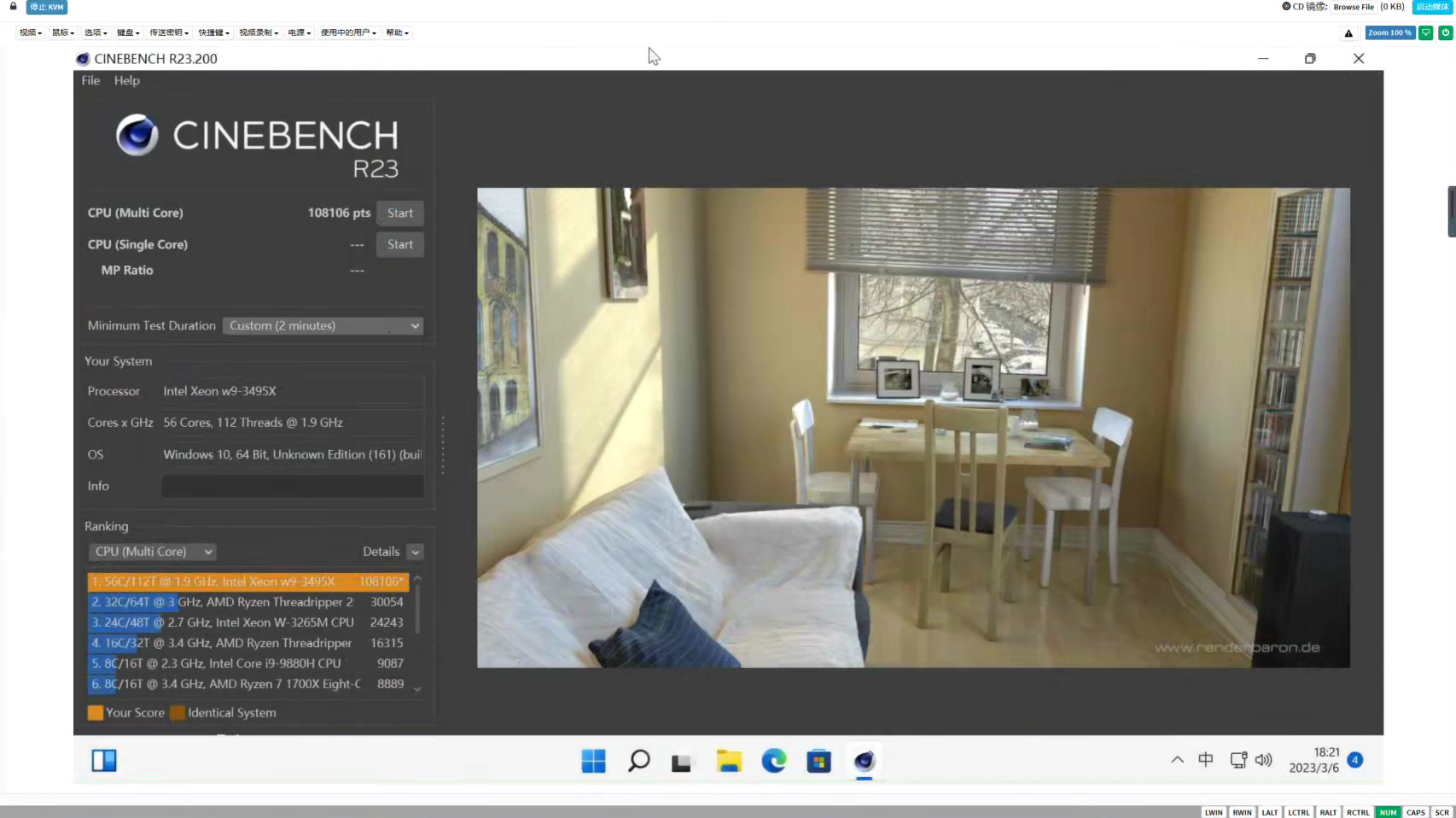
4 图一乐:w9-3495X的R23分数
用的是测Gaussian和ORCA时的超频设置,R23分数108016pts,只跑了2min,若用默认的10min设置,由于偶尔触及功耗上限和温度上限导致部分核心偶尔降频,最终分数会更低一些。
至于其他大众关心的测试项目,@普普通通Tony大叔已于昨晚发布了相关内容,可前往观看。
5 硬件前瞻
2024世代的CPU(intel Redwood+ Cove / Lion Cove和AMD Zen5)的IPC提升很可能比较大,这对GPU加速来说是个好消息,值得期待。具体地说,今年下半年发布的P-Core微内核架构为Redwood Cove (intel 4)的Meteor Lake由于频率和核心数双双退步,故其实际性能并不值得期待(至今不能确定这一代是否有桌面版,看起来极有可能是没了),但可以期待2024年发布的基于Redwood+ Cove (intel 3)微内核架构的Granite Rapids-SP和基于Lion Cove微内核架构的Arrow Lake-S;而AMD Zen5目前只能根据极为有限的信息源了解到IPC有较大提升。
SI
经简单整理的测试结果原始数据(MD_benchmark_data_Mar2023_Pub2.xlsx)。文件下载地址:https://www.aliyundrive.com/s/SizpbDitRtM,提取码:n2k7
文章评论